
Introducción a la clasificación de la red neuronal
Las redes neuronales son la forma más eficiente (sí, lo has leído bien) para resolver problemas del mundo real en Inteligencia Artificial. Actualmente, también es una de las áreas más ampliamente investigadas en informática que se habría desarrollado una nueva forma de red neuronal mientras lee este artículo. Hay cientos de redes neuronales para resolver problemas específicos de diferentes dominios. Aquí vamos a guiarlo a través de diferentes tipos de redes neuronales básicas en el orden de complejidad creciente.
Diferentes tipos de conceptos básicos en la clasificación de redes neuronales
1. Redes neuronales poco profundas (filtrado colaborativo)
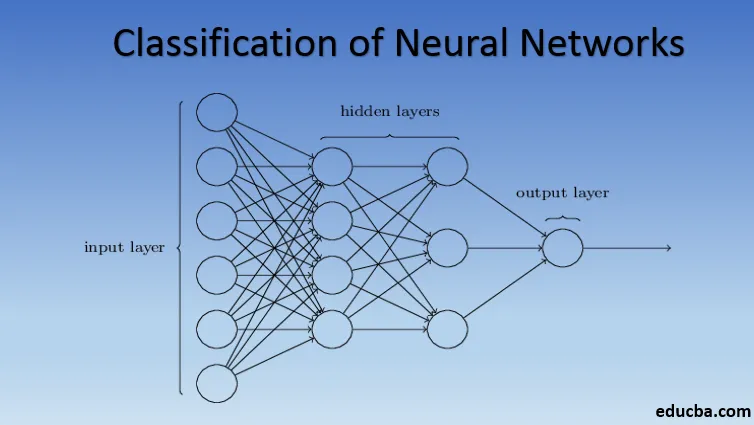
Las redes neuronales están formadas por grupos de perceptrón para simular la estructura neural del cerebro humano. Las redes neuronales poco profundas tienen una sola capa oculta del perceptrón. Uno de los ejemplos comunes de redes neuronales superficiales es el filtrado colaborativo. La capa oculta del perceptrón estaría entrenada para representar las similitudes entre entidades para generar recomendaciones. El sistema de recomendación en Netflix, Amazon, YouTube, etc. utiliza una versión de filtrado colaborativo para recomendar sus productos según el interés del usuario.
2. Perceptrón multicapa (redes neuronales profundas)
Las redes neuronales con más de una capa oculta se denominan redes neuronales profundas. ¡Alerta de spoiler! Todas las redes neuronales siguientes son una forma de red neuronal profunda ajustada / mejorada para abordar problemas específicos del dominio. En general, nos ayudan a alcanzar la universalidad. Dado el número suficiente de capas ocultas de la neurona, una red neuronal profunda puede aproximarse, es decir, resolver cualquier problema complejo del mundo real.
El teorema de aproximación universal es el núcleo de las redes neuronales profundas para entrenar y adaptarse a cualquier modelo. Cada versión de la red neuronal profunda está desarrollada por una capa totalmente conectada de un producto máximo agrupado de multiplicación matricial que está optimizado por algoritmos de retropropagación. Continuaremos aprendiendo las mejoras que resultan en diferentes formas de redes neuronales profundas.
3. Red neuronal convolucional (CNN)
Los CNN son la forma más madura de redes neuronales profundas para producir los resultados más precisos, es decir, mejores que los humanos en la visión por computadora. Las CNN están hechas de capas de convoluciones creadas escaneando cada píxel de imágenes en un conjunto de datos. A medida que los datos se aproximan capa por capa, los CNN comienzan a reconocer los patrones y, por lo tanto, a reconocer los objetos en las imágenes. Estos objetos se usan ampliamente en diversas aplicaciones para identificación, clasificación, etc. Prácticas recientes como el aprendizaje por transferencia en CNN han llevado a mejoras significativas en la inexactitud de los modelos. Google Translator y Google Lens son los ejemplos más avanzados de CNN.
La aplicación de CNN es exponencial, ya que incluso se utilizan para resolver problemas que no están relacionados principalmente con la visión por computadora. Aquí puede encontrar una explicación muy simple pero intuitiva de las CNN.
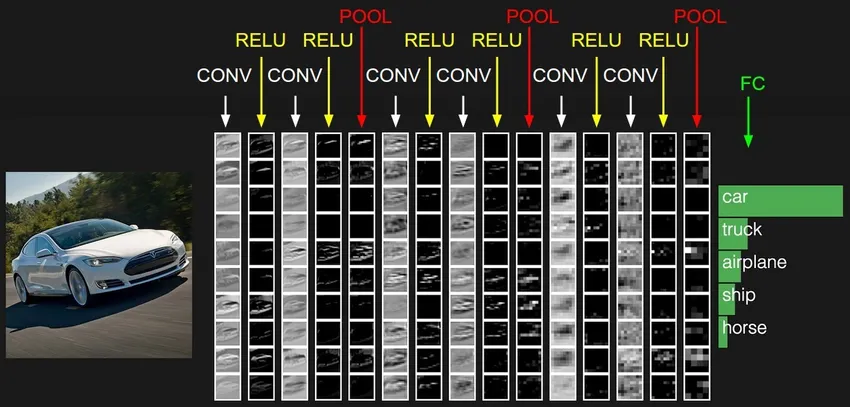
4. Red neuronal recurrente (RNN)
Los RNN son la forma más reciente de redes neuronales profundas para resolver problemas en PNL. En pocas palabras, los RNN retroalimentan la salida de unas pocas capas ocultas a la capa de entrada para agregar y llevar la aproximación a la siguiente iteración (época) del conjunto de datos de entrada. También ayuda al modelo a autoaprender y corrige las predicciones más rápido hasta cierto punto. Dichos modelos son muy útiles para comprender la semántica del texto en las operaciones de PNL. Existen diferentes variantes de RNN como la memoria de corto plazo (LSTM), la unidad recurrente cerrada (GRU), etc. En el siguiente diagrama, la activación de h1 y h2 se alimenta con las entradas x2 y x3 respectivamente.
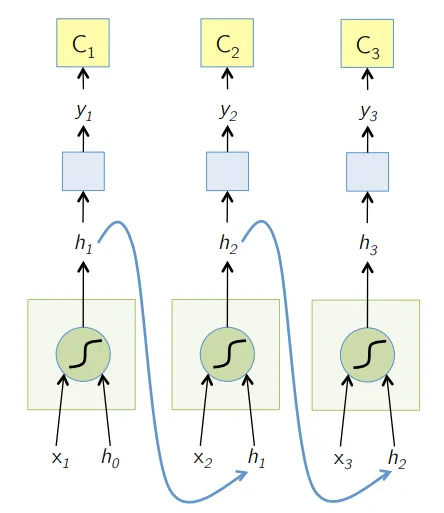
5. Memoria a corto y largo plazo (LSTM)
Los LSTM están diseñados específicamente para abordar el problema de gradientes de fuga con el RNN. Los gradientes de desaparición ocurren con grandes redes neuronales donde los gradientes de las funciones de pérdida tienden a acercarse a cero, lo que hace que las redes neuronales en pausa aprendan. LSTM resuelve este problema al evitar las funciones de activación dentro de sus componentes recurrentes y al no modificar los valores almacenados. Este pequeño cambio dio grandes mejoras en el modelo final que resultó en gigantes tecnológicos que adaptaron LSTM en sus soluciones. A la ilustración "más simple que se explica por sí misma" de LSTM,
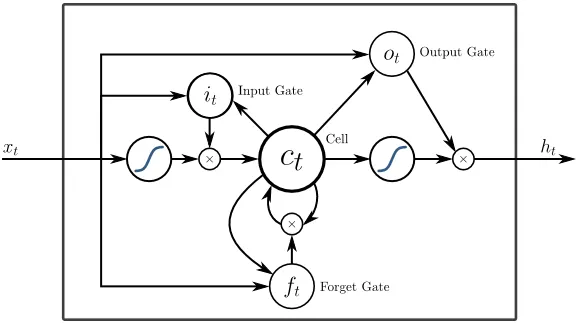
6. Redes basadas en la atención
Los modelos de atención están asumiendo lentamente incluso los nuevos RNN en la práctica. Los modelos de Atención se crean al enfocarse en parte de un subconjunto de la información que se les da, eliminando así la abrumadora cantidad de información de fondo que no es necesaria para la tarea en cuestión. Los modelos de atención se construyen con una combinación de atención suave y dura y se ajustan mediante una atención suave de propagación hacia atrás. Los modelos de atención múltiple apilados jerárquicamente se llaman transformadores. Estos transformadores son más eficientes para ejecutar las pilas en paralelo, de modo que producen resultados de vanguardia con datos y tiempo comparativamente menores para entrenar el modelo. Una distribución de atención se vuelve muy poderosa cuando se usa con CNN / RNN y puede producir una descripción de texto para una imagen de la siguiente manera.

Los gigantes tecnológicos como Google, Facebook, etc., están adaptando rápidamente los modelos de atención para construir sus soluciones.
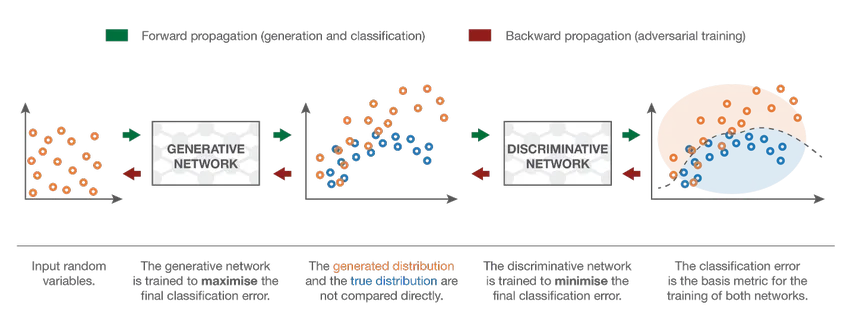
7. Red Adversarial Generativa (GAN)
Aunque los modelos de aprendizaje profundo proporcionan resultados de vanguardia, pueden ser engañados por contrapartes humanas mucho más inteligentes al agregar ruido a los datos del mundo real. Las GAN son el último desarrollo en aprendizaje profundo para abordar tales escenarios. Las GAN utilizan el aprendizaje no supervisado donde las redes neuronales profundas se entrenan con los datos generados por un modelo de IA junto con el conjunto de datos real para mejorar la precisión y la eficiencia del modelo. Estos datos adversos se utilizan principalmente para engañar al modelo discriminatorio con el fin de construir un modelo óptimo. El modelo resultante tiende a ser una mejor aproximación que puede superar dicho ruido. El interés de la investigación en las GAN ha llevado a implementaciones más sofisticadas como la GAN condicional (CGAN), la GAN de pirámide laplaciana (LAPGAN), la GAN de súper resolución (SRGAN), etc.
Conclusión: clasificación de la red neuronal
Las redes neuronales profundas han estado empujando los límites de las computadoras. No se limitan solo a la clasificación (CNN, RNN) o las predicciones (Filtrado colaborativo), sino incluso a la generación de datos (GAN). Estos datos pueden variar desde la bella forma de arte hasta las controvertidas falsificaciones profundas, pero superan a los humanos en una tarea todos los días. Por lo tanto, también deberíamos considerar la ética y los impactos de la IA mientras trabajamos duro para construir un modelo de red neuronal eficiente. Es hora de una infografía ordenada sobre las redes neuronales.
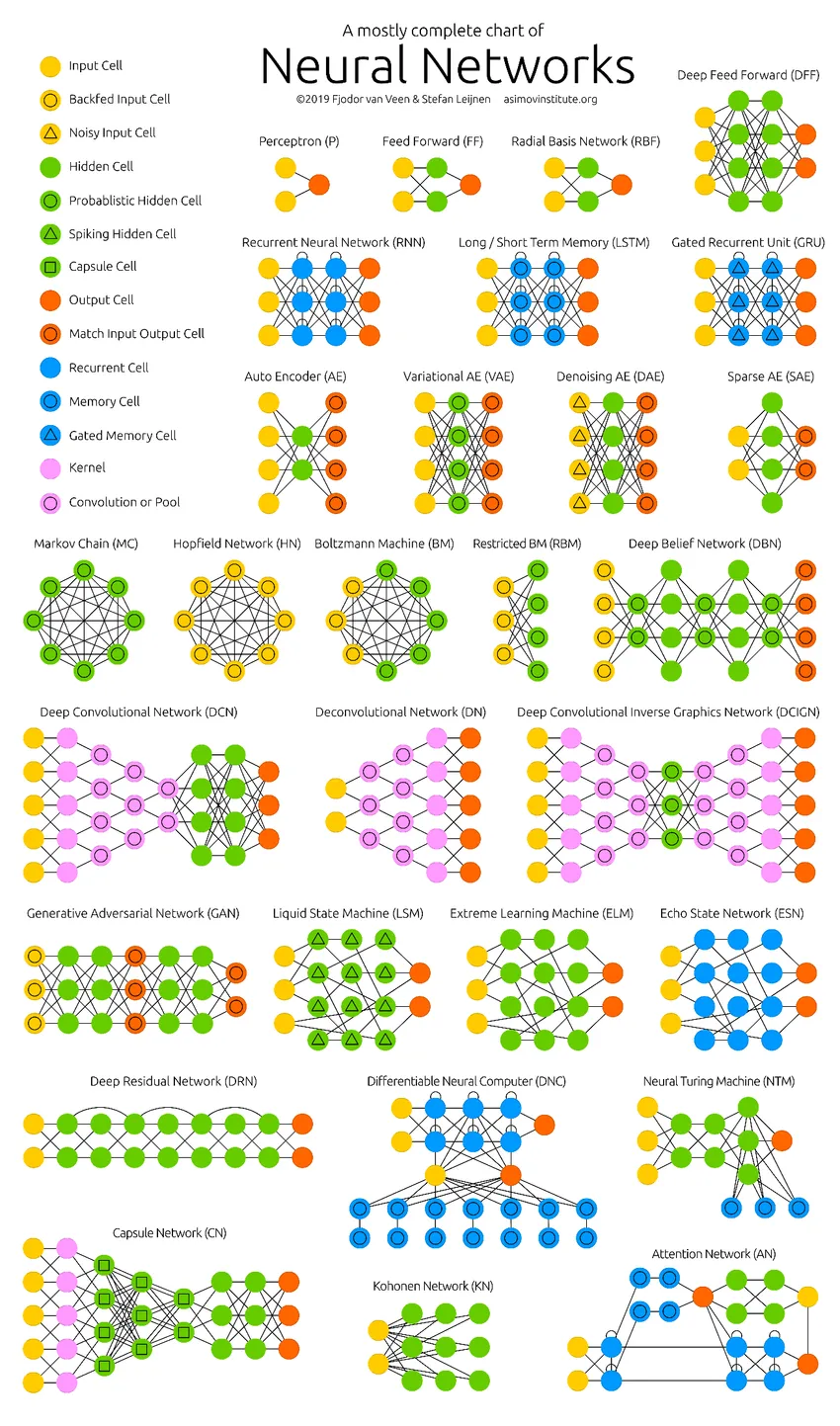
Artículos recomendados
Esta es una guía para la Clasificación de la Red Neural. Aquí discutimos los diferentes tipos de redes neuronales básicas. También puede consultar nuestros artículos para obtener más información.
- ¿Qué son las redes neuronales?
- Algoritmos de red neuronal
- Herramientas de escaneo en red
- Redes neuronales recurrentes (RNN)
- Las 6 mejores comparaciones entre CNN y RNN