
Diferencias entre HashMap y TreeMap
HashMap ha sido parte de la colección de Java. Proporciona la implementación básica de la interfaz de mapa de Java. Los datos se almacenan en pares (clave, valor). Necesita conocer su clave para acceder a un valor. HashMap se conoce como HashMap porque utiliza la técnica Hashing. TreeMap se utiliza para implementar la interfaz de mapa y NavigableMap con la clase abstracta. El mapa se ordena por el orden natural de sus claves o por el comparador proporcionado en el momento de la creación del mapa, según el constructor que se utilice.
Similitudes entre HashMap y TreeMap
Además de las diferencias, existen las siguientes similitudes entre hashmap y treemap:
- Las clases HashMap y TreeMap implementan interfaces serializables y clonables.
- Tanto HashMap como TreeMap extienden la clase AbstractMap.
- Las clases HashMap y TreeMap operan en pares clave-valor.
- Tanto HashMap como TreeMap son colecciones no sincronizadas.
- Tanto HashMap como TreeMap están fallando en las colecciones rápidas.
Ambas implementaciones son parte del marco de recopilación y almacenan datos en pares clave-valor.
Programa Java que muestra HashMap y TreeMap
Aquí hay un programa java que demuestra cómo se colocan y recuperan los elementos del hashmap:
package com.edubca.map;
import java.util.*;
class HashMapDemo
(
// This function prints frequencies of all elements
static void printFrequency(int arr())
(
// Create an empty HashMap
HashMap hashmap =
new HashMap ();
// Iterate through the given array
for (int i = 0; i < arr.length; i++)
(
Integer value = hashmap.get(arr(i));
// If first occurrence of the element
if (hashmap.get(arr(i)) == null)
hashmap.put(arr(i), 1);
// If elements already present in hash map
else
hashmap.put(arr(i), ++value);
)
// Print result
for (Map.Entry m:hashmap.entrySet())
System.out.println("Frequency of " + m.getKey() +
" is " + m.getValue());
)
// Main method to test the above method
public static void main (String() args)
(
int arr() = (10, 40, 5, 12, 5, 7, 10);
printFrequency(arr);
)
)
Salida:
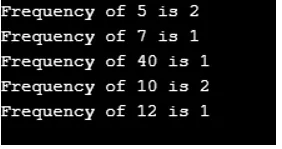
De la salida, está claro que hashmap no mantiene ningún orden. Aquí hay un programa java que muestra cómo se colocan y recuperan los elementos del mapa de árbol.
Código:
package com.edubca.map;
import java.util.*;
class TreeMapDemo
(
// This function prints frequencies of all elements
static void printFrequency(int arr())
(
// Create an empty HashMap
TreeMap treemap =
new TreeMap ();
// Iterate through the given array
for (int i = 0; i < arr.length; i++)
(
Integer value = treemap.get(arr(i));
// If first occurrence of element
if (treemap.get(arr(i)) == null)
treemap.put(arr(i), 1);
// If elements already present in hash map
else
treemap.put(arr(i), ++value);
)
// Print result
for (Map.Entry m: treemap.entrySet())
System.out.println("Frequency of " + m.getKey() +
" is " + m.getValue());
)
// Main method to test above method
public static void main (String() args)
(
int arr() = (10, 40, 5, 12, 5, 7, 10);
printFrequency(arr);
)
)
Salida:
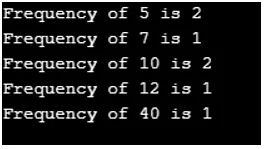
Del resultado, se observa que las claves se ordenan en un orden natural. Por lo tanto, Treemap mantiene el orden ordenado.
Diferencias Head to Head entre HashMap y TreeMap (Infografía)
A continuación se presentan las principales diferencias entre HashMap y TreeMap

Diferencia clave de HashMap vs TreeMap
Los siguientes son los puntos de la diferencia clave HashMap y TreeMap:
1. Estructura e implementación
Hash Map es una implementación basada en tablas hash. Extiende la clase Mapa abstracto e implementa la interfaz Mapa. Un mapa de hash funciona según el principio de hash. La implementación del mapa actúa como una tabla hash agrupada, pero cuando los cubos son demasiado grandes, se convierten en nodos Tree, cada uno con una estructura similar a los nodos de TreeMap. TreeMap extiende la clase de Mapa abstracto e implementa una interfaz de Mapa navegable. La estructura de datos subyacente para el mapa de árbol es un árbol Rojo-Negro.
2. Orden de iteración
El orden de iteración de Hash Map no está definido, mientras que los elementos de un TreeMap se ordenan en orden natural o en un orden personalizado especificado mediante un comparador.
3. Rendimiento
Como Hashmap es una implementación basada en tablas hash, proporciona un rendimiento de tiempo constante que es igual a O (1) para la mayoría de las operaciones comunes. El tiempo requerido para buscar un elemento en un mapa hash es O (1). Pero si hay una implementación incorrecta en el hashmap, esto puede conducir a una sobrecarga de memoria adicional y a una degradación del rendimiento. Por otro lado, TreeMap proporciona un rendimiento de O (log (n)). Dado que el mapa hash se basa en tablas hash, requiere un rango contiguo de memoria, mientras que un mapa de árbol usa solo la cantidad de memoria requerida para contener elementos. Por lo tanto, HashMap es más eficiente en tiempo que el mapa de árbol, pero el mapa de árbol es más eficiente en espacio que HashMap.
4. Manejo nulo
HashMap permite casi una clave nula y muchos valores nulos, mientras que, en un mapa de árbol, nulo no se puede usar como clave, aunque se permiten valores nulos. Si se usa nulo como clave en hashmap, arrojará una excepción de puntero nulo porque internamente usa el método compare o compareTo para ordenar elementos.
Comparación de tabla
Aquí hay una tabla de comparación que muestra las diferencias entre hashmap y treemap:
| Bases de comparación | HashMap | TreeMap |
| Sintaxis | HashMap de clase pública extiende los implementos de AbstractMap Map, Cloneable, Serializable | clase pública TreeMap extiende los implementos AbstractMapNavigableMap, Cloneable, Serializable |
| Ordenar | HashMap no proporciona ningún orden para los elementos. | Los elementos se ordenan en un orden natural o personalizado. |
| Velocidad | Rápido | Lento |
| Claves nulas y valores | Permite casi una clave como valores nulos y múltiples valores nulos. | No permite nulo como clave, pero permite múltiples valores nulos. |
| Consumo de memoria | HashMap consume más memoria debido a la tabla de hash subyacente. | Consume menos memoria en comparación con HashMap. |
| Funcionalidad | Proporciona solo funciones básicas | Proporciona características más ricas. |
| Método de comparación utilizado | Básicamente usa el método equals () para comparar claves. | Utiliza el método compare () o compareTo () para comparar claves. |
| Interfaz implementada | Mapa, serializable y clonable | Mapa navegable, serializable y clonable |
| Actuación | Da un rendimiento de O (1). | Proporciona rendimiento de O (log n) |
| Estructura de datos | Utiliza la tabla hash como estructura de datos. | Utiliza el árbol rojo-negro para el almacenamiento de datos. |
| Elementos homogéneos y heterogéneos. | Permite elementos homogéneos y heterogéneos porque no realiza ninguna clasificación. | Solo permite elementos homogéneos mientras realiza la clasificación. |
| Casos de uso | Se usa cuando no requerimos pares clave-valor en orden ordenado. | Se usa cuando se requiere ordenar los pares clave-valor de un mapa. |
Conclusión
Del artículo, se concluye que hashmap es una implementación de propósito general de la interfaz Map. Proporciona rendimiento de O (1) mientras que Treemap proporciona un rendimiento de O (log (n)). Por lo tanto, HashMap suele ser más rápido que TreeMap.
Artículos recomendados
Esta es una guía de HashMap vs TreeMap. Aquí discutimos la introducción a HashMap vs TreeMap, las diferencias entre Hashmap y Treemap y una tabla de comparación. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- WebLogic vs JBoss
- Lista vs conjunto
- Git Fetch vs Git Pull
- Kafka vs Spark | Principales diferencias
- Las 5 principales diferencias de Kafka vs Kinesis