

Introducción a ANOVA en R
El siguiente artículo ANOVA en R proporciona un esquema para comparar el valor medio de diferentes grupos. Un análisis de varianza (ANOVA) es una técnica muy común utilizada para comparar el valor medio de diferentes grupos. El modelo ANOVA se usa para la prueba de hipótesis, donde se genera cierta suposición o parámetro para una población y el método estadístico se usa para determinar si la hipótesis es verdadera o falsa.
La hipótesis se deriva de la suposición del investigador y la información disponible sobre la población. ANOVA se llama Análisis de varianza y se usa para la prueba de hipótesis donde se requiere medir las medias de una variable en múltiples grupos independientes.
Por ejemplo, en un laboratorio para estudiar o inventar un nuevo medicamento para la obesidad, los investigadores compararán el resultado del tratamiento experimental y estándar. En un estudio de obesidad, se pueden obtener resultados valiosos cuando la tasa media de obesidad de la población se puede comparar en diferentes grupos de edad. En este caso, uno quisiera observar la tasa media de obesidad entre los diferentes grupos de edad, como la edad (5 a 18), (19, 35) y (36 a 50). El método ANOVA se aplica ya que hay más de dos grupos que son independientes. El método ANOVA se utiliza para comparar la obesidad media de los grupos independientes. Se utiliza la función aov () y la sintaxis es aov (fórmula, datos = marco de datos) En este artículo, aprenderemos sobre el modelo ANOVA y discutiremos el modelo ANOVA unidireccional y bidireccional junto con ejemplos.
¿Por qué ANOVA?
- Esta técnica se utiliza para responder a la hipótesis mientras se analizan múltiples grupos de datos. Existen múltiples enfoques estadísticos, sin embargo, el ANOVA en R se aplica cuando la comparación debe hacerse en más de dos grupos independientes, como en nuestro ejemplo anterior, tres grupos de edad diferentes.
- La técnica ANOVA mide la media de los grupos independientes para proporcionar a los investigadores el resultado de la hipótesis. Para obtener resultados precisos, se deben tener en cuenta las medias de muestra, el tamaño de muestra y la desviación estándar de cada grupo individual.
- Es posible observar la media individualmente para cada uno de los tres grupos para la comparación. Sin embargo, este enfoque tiene limitaciones y puede resultar incorrecto porque estas tres comparaciones no consideran los datos totales y, por lo tanto, pueden provocar un error de tipo 1. R nos proporciona la función de realizar el análisis ANOVA para examinar la variabilidad entre los grupos independientes de datos. Hay cinco etapas para realizar el análisis ANOVA. En la primera etapa, los datos se organizan en formato csv y la columna se genera para cada variable. Una de las columnas sería una variable dependiente y las restantes son la variable independiente. En la segunda etapa, los datos se leen en R studio y se nombran adecuadamente. En la tercera etapa, un conjunto de datos se adjunta a variables individuales y la memoria lo lee. Finalmente, el ANOVA en R se define y analiza. En las secciones a continuación, proporcioné un par de ejemplos de casos de estudio en los que se deben utilizar técnicas ANOVA.
- Se probaron seis insecticidas en 12 campos cada uno, y los investigadores contaron el número de errores que quedaban en cada campo. Ahora los agricultores necesitan saber si los insecticidas hacen alguna diferencia y, de ser así, cuál usan mejor. Responde esta pregunta utilizando la función aov () para realizar un ANOVA.
- Cincuenta pacientes recibieron uno de los cinco tratamientos farmacológicos reductores del colesterol (trt). Tres de las condiciones de tratamiento involucraron el mismo medicamento administrado como 20 mg una vez al día (1 vez) 10 mg dos veces al día (2 veces) 5 mg cuatro veces al día (4 veces). Las dos condiciones restantes (drugD y drugE) representaban fármacos competidores. ¿Qué tratamiento farmacológico produjo la mayor reducción (respuesta) de colesterol?
ANOVA unidireccional
- El método unidireccional es una de las técnicas ANOVA básicas en las que se aplica el análisis de varianza y se compara el valor medio de múltiples grupos de población.
- ANOVA unidireccional obtuvo su nombre debido a la disponibilidad de datos clasificados unidireccionales. En un ANOVA unidireccional, una sola variable dependiente y una o más variables independientes pueden estar disponibles.
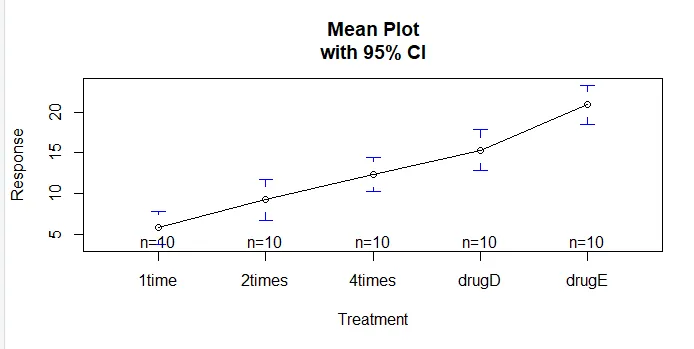
- Por ejemplo, realizaremos la técnica ANOVA en el conjunto de datos de colesterol. El conjunto de datos consta de dos variables trt (que son tratamientos en 5 niveles diferentes) y variables de respuesta. Variable independiente - grupos de tratamiento farmacológico, variable dependiente - medias de 2 o más grupos ANOVA. A partir de estos resultados, puede confirmar que tomar las dosis de 5 mg 4 veces al día fue mejor que tomar una dosis de veinte mg una vez al día. El medicamento D tiene mejores efectos en comparación con ese medicamento E
El medicamento D proporciona mejores resultados si se toma en dosis de 20 mg en comparación con el medicamento E
Utiliza el conjunto de datos de colesterol en el paquete multicomp.install.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
La prueba ANOVA F para el tratamiento (trt) es significativa (p <.0001), lo que proporciona evidencia de que los cinco tratamientos
# no son todos igualmente efectivos.
resumen (aov_model)
desprender (colesterol)

La función plotmeans () en el paquete gplots se puede usar para producir un gráfico de medias grupales y sus intervalos de confianza. Esto muestra claramente las diferencias de tratamientoinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
Examinemos la salida de TukeyHSD () para las diferencias por pares entre las medias de grupo
TukeyHSD (aov_model)
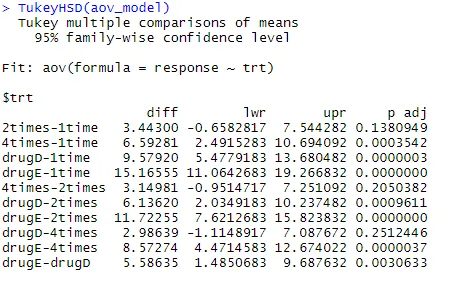
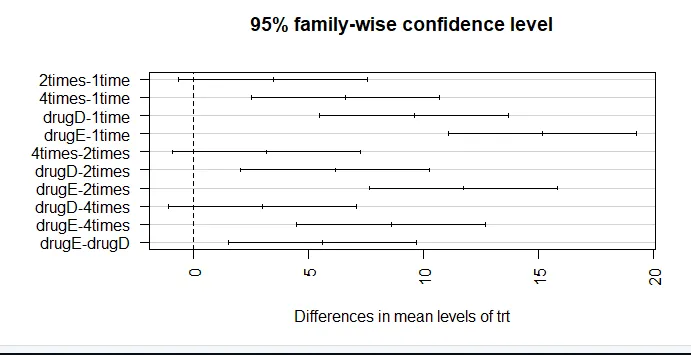
Las reducciones medias de colesterol durante 1 vez y 2 veces no son significativamente diferentes entre sí (p = 0, 138), mientras que la diferencia entre 1 vez y 4 veces es significativamente diferente (p <0, 001).
par (mar = c (5, 8, 4, 2)) # aumenta la gráfica del margen izquierdo (TukeyHSD (aov_model), las = 2)
La confianza en los resultados depende del grado en que sus datos satisfagan los supuestos subyacentes a las pruebas estadísticas. En un ANOVA unidireccional, se supone que la variable dependiente se distribuye normalmente y tiene la misma varianza en cada grupo. Puede usar un gráfico QQ para evaluar la biblioteca de suposición de normalidad (automóvil).
Gráfico QQ (lm (respuesta ~ trt, datos = colesterol), simulación = VERDADERO, principal = "Gráfico QQ", etiquetas = FALSO)
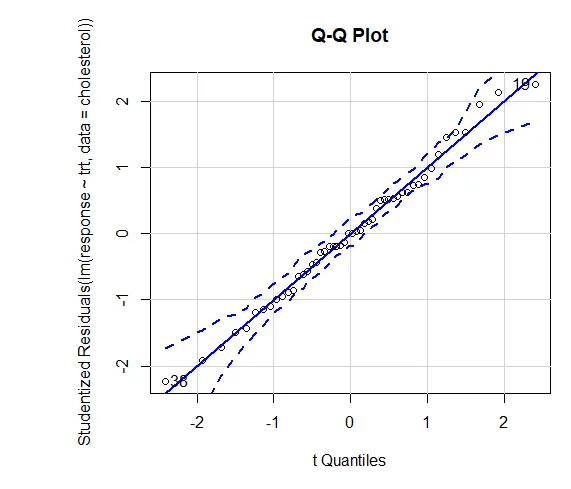
Línea de puntos = 95% de confianza, lo que sugiere que el supuesto de normalidad se ha cumplido bastante bien. ANOVA supone que las variaciones son iguales entre los grupos o muestras. La prueba de Bartlett se puede usar para verificar esa suposición
bartlett.test (respuesta ~ trt, datos = colesterol). La prueba de Bartlett indica que las variaciones en los cinco grupos no difieren significativamente (p = 0.97).
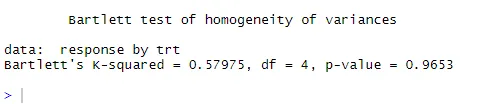
ANOVA también es sensible a la prueba de valores atípicos para los valores atípicos que utilizan la función outlierTest () en el paquete del automóvil. Es posible que no necesite ejecutar este paquete para actualizar la biblioteca de su automóvil.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
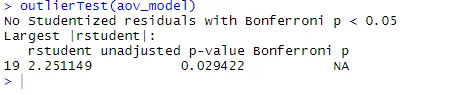
De la salida, puede ver que no hay indicios de valores atípicos en los datos de colesterol (NA ocurre cuando p> 1). Tomando el gráfico QQ, la prueba de Bartlett y la prueba de valores atípicos juntos, los datos parecen ajustarse bastante bien al modelo ANOVA.
Anova bidireccional
Se agrega otra variable en la prueba ANOVA de dos vías. Cuando hay dos variables independientes, necesitaremos usar la técnica ANOVA de dos vías en lugar de la técnica ANOVA de una vía que se utilizó en el caso anterior en el que teníamos una variable dependiente continua y más de una variable independiente. Para verificar ANOVA bidireccional, se deben cumplir múltiples supuestos.
- Disponibilidad de observaciones independientes.
- Las observaciones deben distribuirse normalmente
- La varianza debe ser igual en las observaciones.
- Los valores atípicos no deben estar presentes
- Errores independientes
Para verificar el ANOVA de dos vías, se agrega otra variable llamada BP al conjunto de datos. La variable indica la tasa de presión arterial en pacientes. Nos gustaría verificar si hay alguna diferencia estadística entre la PA y la dosis administrada a los pacientes.
df <- read.csv ("archivo.csv")
df
anova_two_way <- aov (respuesta ~ trt + BP, data = df)
resumen (anova_two_way)
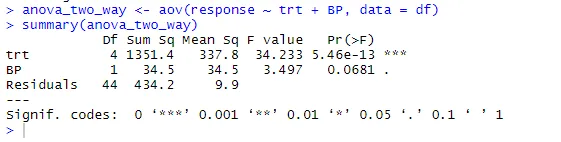
A partir de la salida, se puede concluir que tanto la trt como la BP son estadísticamente diferentes de 0. Por lo tanto, la hipótesis nula puede ser rechazada.
Beneficios de ANOVA en R
La prueba ANOVA determina la diferencia en la media entre dos o más grupos independientes. Esta técnica es muy útil para el análisis de múltiples artículos, que es esencial para el análisis de mercado. Usando la prueba ANOVA, uno puede obtener los conocimientos necesarios de los datos. Por ejemplo, durante una encuesta de productos en la que se recopilan múltiples datos, como listas de compras, me gusta y no me gusta de los usuarios. La prueba ANOVA nos ayuda a comparar grupos de la población. El grupo podría ser masculino versus femenino o varios grupos de edad. La técnica ANOVA ayuda a distinguir entre los valores medios de los diferentes grupos de la población que de hecho son diferentes.
Conclusión - ANOVA en R
ANOVA es uno de los métodos más utilizados para la prueba de hipótesis. En este artículo, hemos realizado una prueba ANOVA en el conjunto de datos que consta de cincuenta pacientes que recibieron tratamiento farmacológico para reducir el colesterol y también hemos visto cómo se puede realizar ANOVA bidireccional cuando hay disponible una variable independiente adicional.
Artículos recomendados
Esta es una guía de ANOVA en R. Aquí discutimos el modelo de Anova de una vía y de dos vías junto con ejemplos y beneficios de ANOVA. También puede consultar nuestros otros artículos sugeridos:
- Regresión vs ANOVA
- ¿Qué es el SPSS?
- Cómo interpretar los resultados usando la prueba ANOVA
- Funciones en R