
¿Qué es Splunk?
Splunk se conoce como un producto o herramienta, que se utiliza para analizar datos en grandes volúmenes en el mundo empresarial. Es una herramienta de búsqueda muy potente y versátil que completa un registro en tiempo real y, por lo tanto, facilita el monitoreo y la resolución de problemas que ocurren en nuestra aplicación. Los fundadores de Splunk son Michael Baum, Rob Das y Erik Swan. Se desarrolló en 2003, pero Splunk tiene más demanda después de su lanzamiento Splunk 3.0 en 2008-09.
Splunk funciona como indexación de los datos, utiliza los datos para buscar e investigar, agregar conocimiento a sus datos, configurar monitores y alertas, informar y analizar, preparar paneles. Splunk recopila los datos de forma segura y luego ayuda a almacenar e indexar los datos en una ubicación centralizada con acceso basado en roles. Por lo tanto, no importa cuán desestructurados o diversos sean nuestros datos, quizás podamos monitorear, informar y analizar fácilmente nuestros datos.
Conceptos de Splunk:
Splunk agrega conocimiento a sus datos con la ayuda de objetos de conocimiento (como etiquetas, campos y búsquedas guardadas, informes, paneles, alertas, etc.). Estos objetos de conocimiento se pueden compartir y reutilizar: estos conceptos de objetos de conocimiento se explican a continuación:
Sobre Splunk Home:
Splunk Home es la ventana principal de las aplicaciones y los datos accesibles desde esta Splunk. Splunk Home incluye una barra de búsqueda y tres paneles: Aplicaciones, Datos y Ayuda.
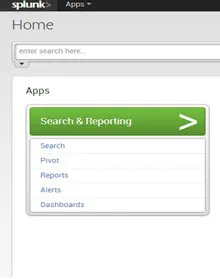
- El usuario utiliza esta barra de búsqueda de aplicaciones para ejecutar la consulta de búsqueda. La barra de búsqueda de aplicaciones y la barra de búsqueda estándar de Splunk son similares e incluyen un selector de rango de tiempo.
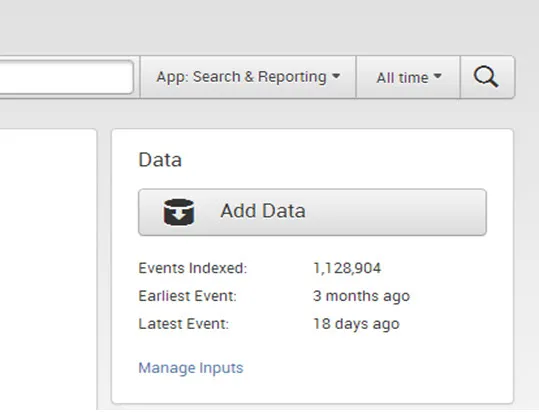
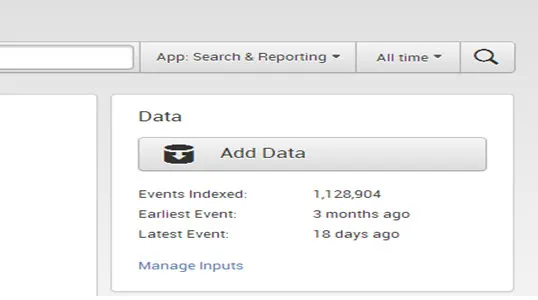
- El usuario utiliza el panel de Datos para agregar nuevos datos y administrarlos. Muestra cuánto tiempo atrás se indexaron los datos del primer y último evento de datos y el volumen de datos.
Cuando tiene datos en Splunk, puede ver un breve resumen:
- Haga clic en Agregar datos para obtener nuevos datos en Splunk.
- Haga clic en Administrar entradas para ver y editar las definiciones de entrada existentes.
Carga de datos en Splunk:
Un usuario puede cargar un tipo diferente de datos como archivos de texto, archivos csv, registros de eventos, weblogs, cualquier dato de máquina en Splunk. Después de cargar los datos, Splunk los indexa de inmediato y los pone a disposición para la búsqueda. Un usuario puede realizar cualquier tipo de búsqueda en estos datos y puede crear informes, paneles y gráficos, etc.
Paso 1. Haz clic en Agregar datos, en Splunk Home.
Paso 2. Haz clic en los archivos y directorios.
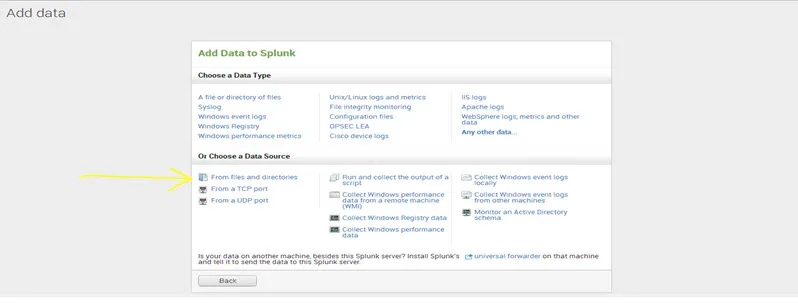
Paso 3. Hay dos opciones de vista previa de datos antes de indexar y omitir la vista previa. Si desea obtener una vista previa de los datos antes de indexar, seleccione los datos de vista previa y explore el archivo; de lo contrario, seleccione omitir vista previa y presione continuar.
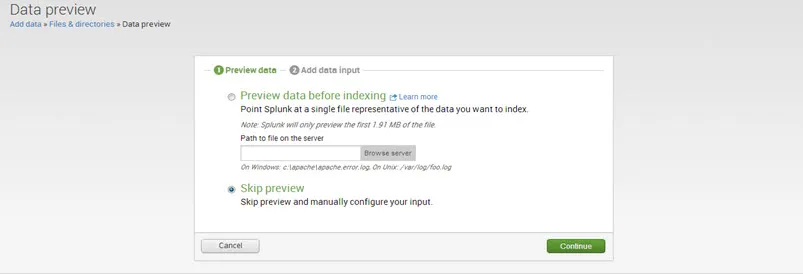
Paso 4. Seleccione Cargar e indexar un archivo y busque el archivo de datos.
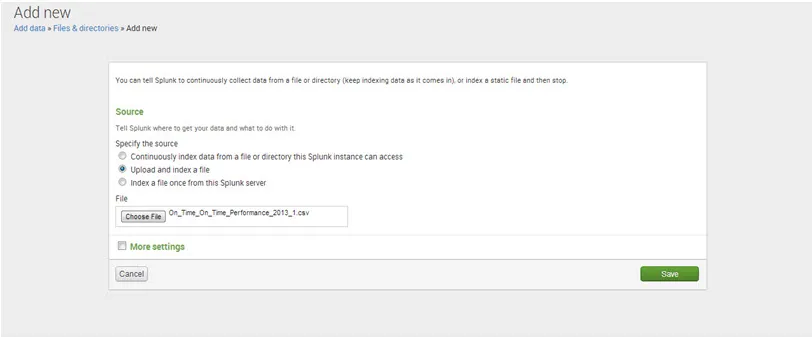
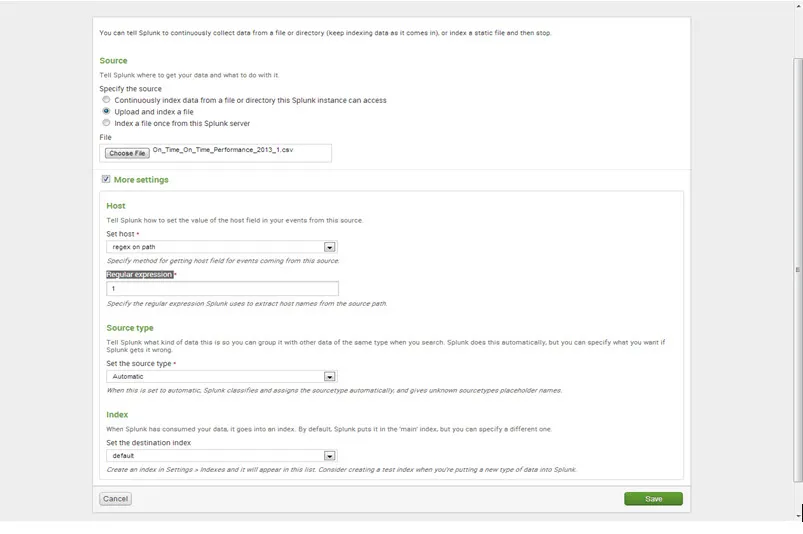
Paso 5. Más configuraciones
- En Host, establezca los valores de un host Set en "regex en una ruta" y Expresión regular en "1"
- En el tipo de fuente, establezca el valor del conjunto, el tipo de fuente es "Automático".
- Debajo del conjunto de índices, el valor de establecer el índice de destino como "predeterminado".
Paso 6. Haz clic en guardar y Splunk muestra un mensaje que los datos se están indexando correctamente.
Para comenzar la búsqueda, haga clic en comenzar a buscar.
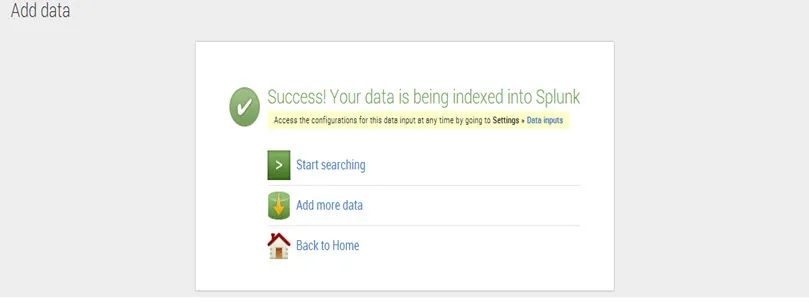
¿Qué es el resumen de datos de Splunk?
Para ver más detalles sobre los datos cargados, haga clic en Resumen de datos.
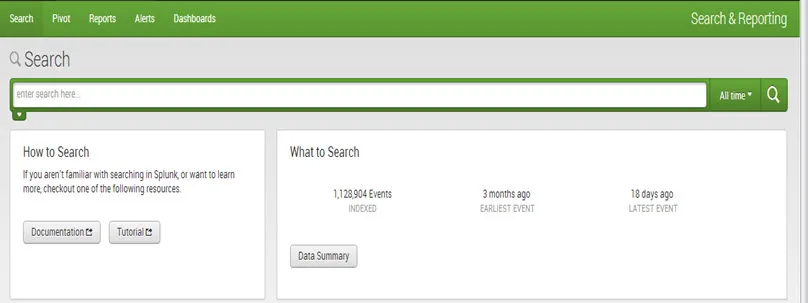
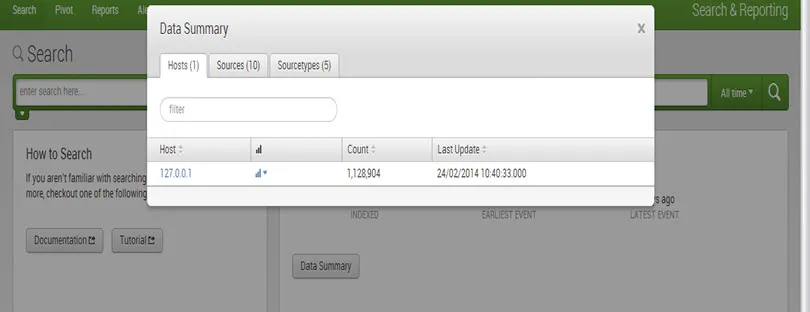
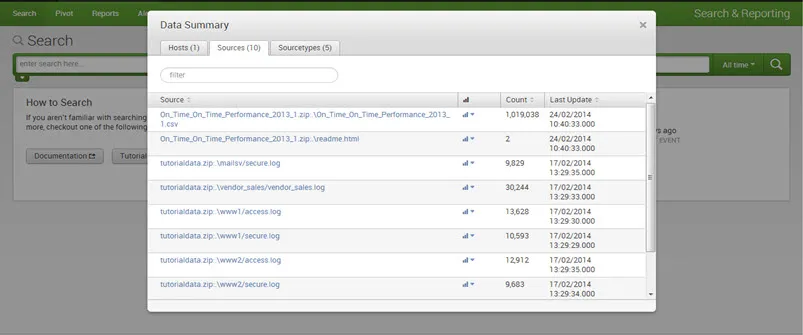
Cuadro de diálogo Resumen de datos que muestra tres pestañas: Hosts, Orígenes, Tipos de origen.
El host de un evento suele ser el nombre de host, la dirección IP o el nombre de dominio completo de la máquina de red.
El origen de un evento es la ruta del archivo o directorio, el puerto de red o el script.
El tipo de evento de origen le indica qué tipo de datos son, generalmente en función de cómo está formateado.
Búsqueda / Búsqueda avanzada:
Comandos más utilizados:
Top / Rare: este comando devuelve los valores superiores y raros del campo dado en la barra de búsqueda.
P.ej:

Salida:
Estadísticas: El comando de estadísticas se usa para cálculos estadísticos sobre un conjunto de datos. Es similar a la agregación SQL. Hay más de un comando para cálculos estadísticos. Los comandos de estadísticas, gráfico y gráfico de tiempo realizan los mismos cálculos estadísticos en sus datos, pero devuelven resultados ligeramente diferentes.
P.ej:
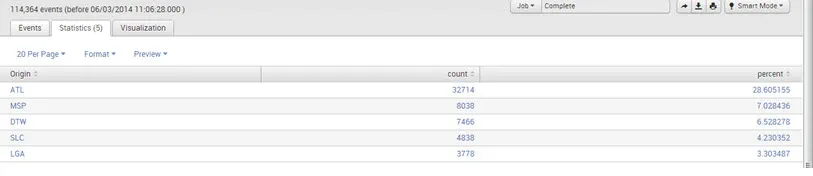
- Tipo de fuente = "csv" | stats dc (origen)

Salida:

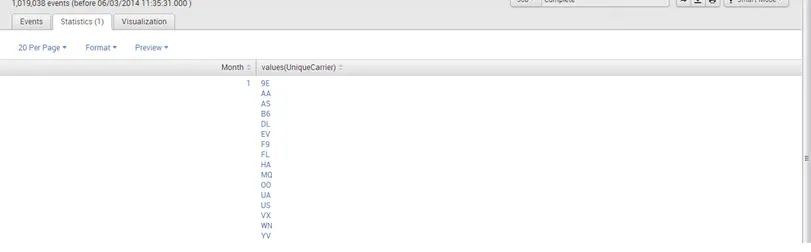
- sourcetype = "csv" | valores de estadísticas (UniqueCarrier) por mes

Salida:
A continuación se muestran las funciones estadísticas que puede usar con el comando de estadísticas.
Promedio (X): Devuelve el promedio de los valores del campo X.
Count (X): Devuelve el número de ocurrencias del campo X.
Dc (X): devuelve el recuento de valores distintos del campo X.
Max (X): devuelve el valor máximo del campo X.
Min (X): devuelve el valor mínimo del campo X.
Suma (X): Devuelve la suma de los valores del campo X.
Valores (X): devuelve una lista de todos los valores distintos del campo X
Gráfico: El comando de gráfico crea una salida de datos tabulares adecuada para gráficos. Usted especifica la variable del eje x usando over o by.
Por ejemplo: sourcetype = ”csv” | valores del gráfico (UniqueCarrier) por mes

Salida:
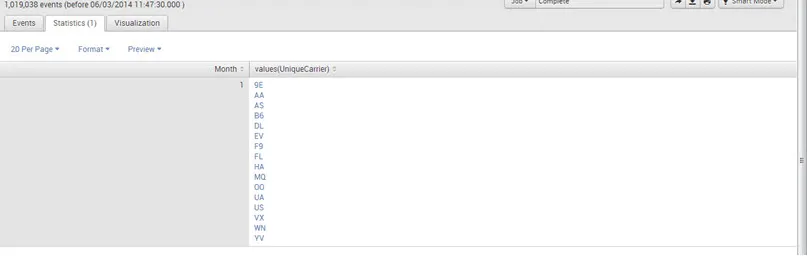
Diagrama de tiempo: el comando de diagrama de tiempo crea un gráfico para una agregación estadística aplicada
a un campo contra el tiempo como el eje x.
Por ejemplo: sourcetype = ”csv” | valores de diagrama de tiempo (UniqueCarrier) por mes

Salida:
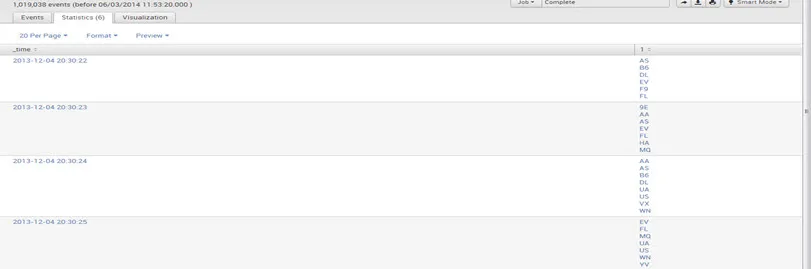
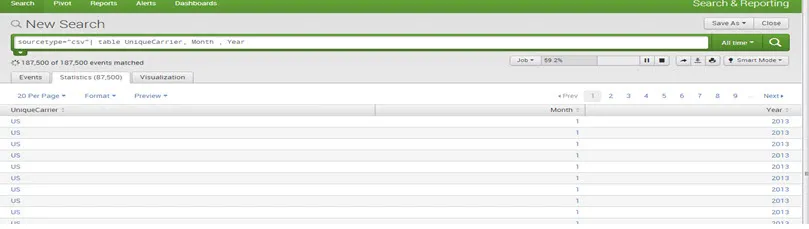
Tabla: este comando devuelve una tabla formada por los campos utilizados en la lista de argumentos de búsqueda
P.ej:
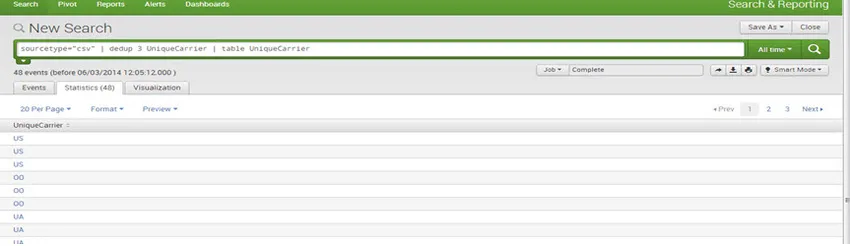
Dedup: la eliminación de datos redundantes es el objetivo del comando de filtrado dedup.
P.ej:
Visualizaciones:
Gráficos / informes Podemos crear informes y gráficos para una mejor visualización y comprensión. Se pueden dibujar todo tipo de gráficos. Por ejemplo Pie, Line, Bar y Area, etc.
P.ej:
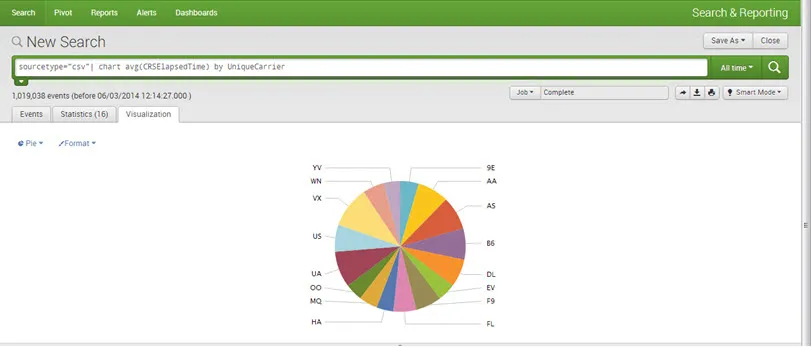
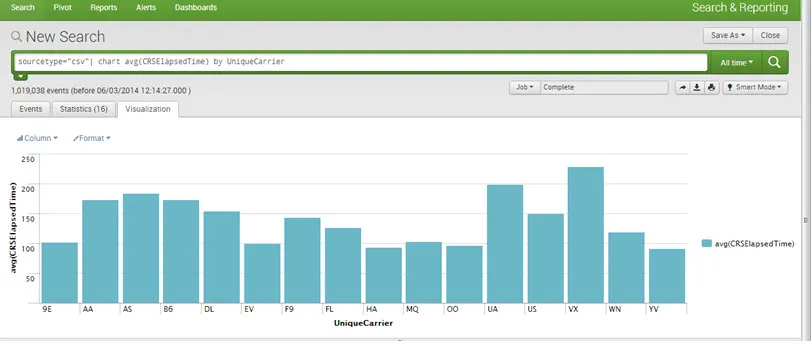
Paneles de control:
Los paneles son los tipos de vistas más comunes. Cada panel contiene uno o más paneles, cada uno de los cuales puede contener visualizaciones como gráficos, tablas, listas de eventos y mapas. Básicamente, los paneles son una colección de búsquedas e informes.
Para crear un tablero, guarde un gráfico / informe como panel del tablero.
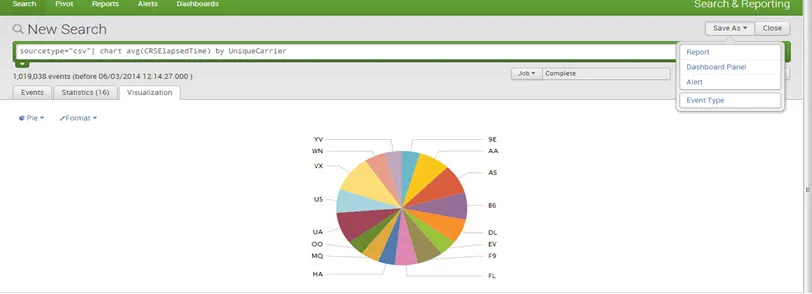 Mencione el título, la descripción y el título del panel y guárdelo.
Mencione el título, la descripción y el título del panel y guárdelo.
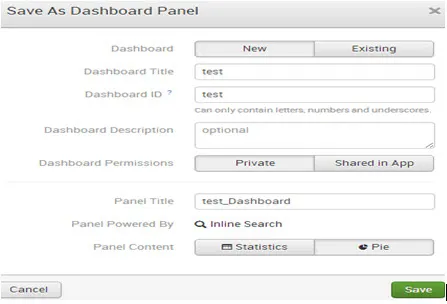
El tablero de instrumentos se ha creado con éxito. Y compite por hacer clic en el panel de visualización.

Salida:
Conclusión: ¿qué es Splunk?
Splunk es la plataforma que se utiliza para operaciones en tiempo real. Se utiliza para la gestión de aplicaciones, seguridad y gestión del rendimiento. Está disponible de forma gratuita y es de fácil acceso. Ayuda a visualizar los datos con la ayuda de cuadros y gráficos. Puede ser fácil de aprender para los principiantes. También es uno de los principales productos o herramientas para los desarrolladores de DevOps y Agile.
Artículos recomendados:
Esta ha sido una guía de lo que es Splunk. Aquí hemos discutido algunos conceptos básicos de Splunk, pasos para cargar datos en Splunk, etc. También puede consultar el siguiente artículo para obtener más información:
- Preguntas y respuestas de la entrevista de Splunk
- Splunk vs Spark diferencias
- Hadoop vs Splunk - Encuentra las 7 mejores diferencias