
Diferencia entre colmena y HBase
Apache Hive y HBase son tecnologías de big data basadas en Hadoop. Ambos solían consultar datos. Hive y HBase se ejecutan sobre Hadoop y difieren en su funcionalidad. Hive es un dialecto SQL basado en reducción de mapas, mientras que HBase solo admite MapReduce. HBase almacena datos en forma de pares clave / valor o familia de columnas, mientras que Hive no almacena datos.
Head to Head diferencias entre Hive vs HBase (Infografía)
A continuación se muestra la diferencia de los 8 principales entre Hive y HBase
Diferencias clave entre Hive y HBase
- Hbase es compatible con ACID, mientras que Hive no.
- Hive admite particiones y criterios de filtro basados en el formato de fecha, mientras que HBase admite particiones automáticas.
- Hive no admite declaraciones de actualización, mientras que HBase las admite.
- Hbase es más rápido en comparación con Hive en la obtención de datos.
- Hive se utiliza para procesar datos estructurados, mientras que HBase, dado que no tiene esquemas, puede procesar cualquier tipo de datos.
- Hbase es altamente (horizontalmente) escalable en comparación con Hive.
- Hive analiza los datos en el HDFS con el soporte de consultas SQL y luego los convierte en un mapa y reduce los trabajos, mientras que en Hbase, ya que es una transmisión en tiempo real, realiza directamente sus operaciones en la base de datos al particionar en tablas y familias de columnas.
- Cuando se realiza la consulta de datos, Hive utiliza un shell conocido como Hive Shell para emitir los comandos, mientras que HBase, dado que es una base de datos, usaremos un comando para procesar los datos en HBase.
- Para ir al shell de Hive usaremos el comando hive. Después de dar esto, aparecerá como colmena>. En HBase, simplemente damos como Usar HBase.
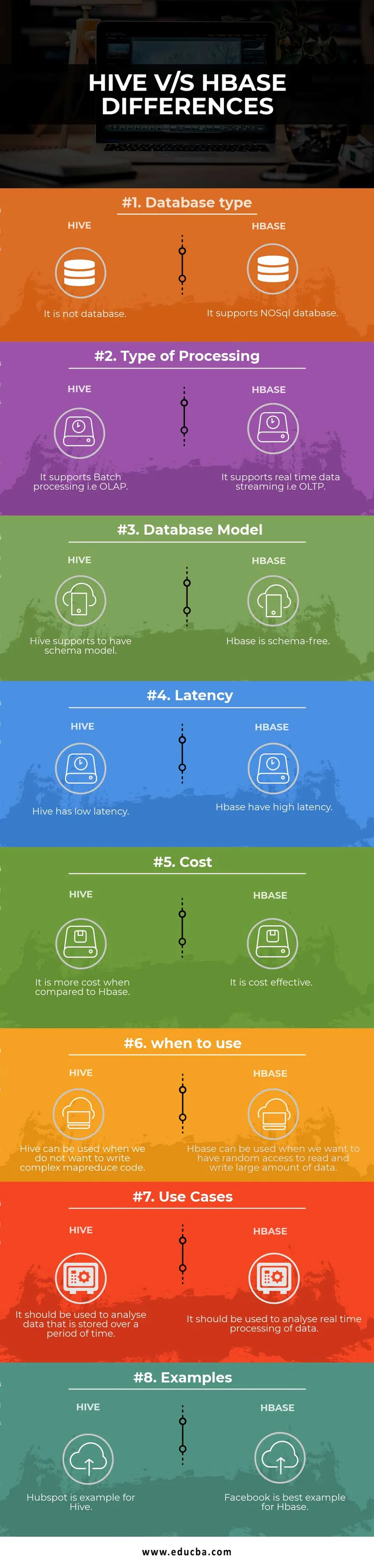
Tabla de comparación de colmena vs HBase
| Bases para la comparación | Colmena | Hbase |
| Tipo de base de datos | No es una base de datos | Es compatible con la base de datos NoSQL |
| Tipo de procesamiento | Es compatible con el procesamiento por lotes, es decir, OLAP | Es compatible con la transmisión de datos en tiempo real, es decir, OLTP |
| Modelo de base de datos | La colmena admite tener un modelo de esquema | Hbase no tiene esquema |
| Latencia | La colmena tiene baja latencia | Hbase tiene alta latencia |
| Costo | Es más costoso en comparación con HBase | Es rentable |
| cuándo usar | Hive se puede usar cuando no queremos escribir código MapReduce complejo | HBase se puede usar cuando queremos tener acceso aleatorio para leer y escribir una gran cantidad de datos |
| Casos de uso | Debe usarse para analizar datos almacenados durante un período de tiempo | Debe usarse para analizar el procesamiento de datos en tiempo real. |
| Ejemplos | Hubspot es un ejemplo para Hive | Facebook es el mejor ejemplo para Hbase |
Diferencias en la codificación entre Hive vs HBase
Discutamos ahora las diferencias básicas entre Hive y HBase en la codificación.
| Bases para la comparación | Colmena | Hbase |
| Para crear una base de datos | CREAR BASE DE DATOS (SI NO EXISTE) NOMBRE DE BASE DE DATOS; | Como Hbase es una base de datos, no necesitamos crear una base de datos específica |
| Para soltar una base de datos | DROP DATABASE (SI EXISTE) NOMBRE DE LA BASE DE DATOS (RESTRICCIÓN O CASCADA); | N / A |
| Para crear una tabla | CREAR TABLA (TEMPORAL O EXTERNA) (SI NO EXISTE) NOMBRE-TABLA ((nombre-columna tipo_datos (comentario columna-comentario), ….)) (comentario tabla_comentario) (FORMATO DE FILA formato de fila) (Almacenado como formato de archivo) | CREAR '', '' |
| Para alterar una mesa | ALTER TABLE name RENAME TO new-name
ALTER TABLE name DROP (COLUMN) nombre-columna ALTER TABLE name ADD COLUMNS (col-spec (, col-spec ..)) ALTER TABLE name CHANGE column-name new-name new-type ALTER TABLE name REPLACE COLUMNS (col-spec (, col-spec ..)) | ALTERE 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Deshabilitar una mesa | N / A | deshabilite 'TABLE-NAME' -> para deshabilitar el nombre de tabla especificado
disable_all 'r *' -> para deshabilitar todas las tablas que coinciden con la expresión regular |
| Habilitar una mesa | N / A | habilitar 'TABLE-NAME' |
| Para soltar una mesa | DROP TABLE IF EXISTS nombre-tabla | Si queremos soltar una tabla, primero debemos deshabilitarla
deshabilitar 'nombre-tabla' soltar 'nombre-tabla' Del mismo modo, podemos usar disable_all y drop_all para eliminar las tablas que coinciden con la expresión regular especificada. |
| Para enumerar bases de datos | mostrar bases de datos; | N / A |
| Para enumerar tablas en la base de datos | mostrar tablas; | lista |
| Describir el esquema de una tabla. | describe el nombre de la tabla; | describe 'table-name' |
Integración de Hive vs HBase
- Instalar y configurar Hive.
- Instalar y configurar HBase.
- Para la integración de Hive y HBase, utilizamos MANIPULADORES DE ALMACENAMIENTO en Hive.
- Storage Handlers es una combinación de SERDE, InputFormat, OutputFormat que acepta cualquier entidad externa como una tabla en Hive.
- Entonces, esta característica ayuda al usuario a emitir consultas SQL, ya sea que la tabla esté presente en Hadoop o en la base de datos basada en NOSQL como HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Ahora veremos un ejemplo para conectar Hive con HBase usando HiveStorageHandler:
- Primero, necesitamos crear una tabla Hbase usando el comando.
crear 'Estudiante', 'información personal', 'información del departamento'
-> La información personal y la información del departamento crean dos familias de columnas diferentes en la tabla Estudiante.
- Necesitamos insertar algunos datos en la tabla de Alumno, por ejemplo, como se menciona a continuación.
poner 'estudiante', 'sid01 ′, ' personalinfo: nombre ', ' Ram '
poner 'estudiante', 'sid01 ′, ' personalinfo: mailid ', ' '
poner 'estudiante', 'sid01 ′, ' deptinfo: deptname ', ' Java '
poner 'Estudiante', 'sid01 ′, ' deptinfo: joinyear ', ' 1994 ′
-> Del mismo modo, podemos crear datos para sid02, sid03 …
- Ahora necesitamos crear una tabla Hive que apunte a la tabla HBase.
- Para cada columna en Hbase, crearemos una tabla particular para esa columna en Hive. En este caso, crearemos 2 tablas en Hive
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Del mismo modo, necesitamos crear una tabla de detalles de información del departamento en la colmena.
- Ahora podemos escribir consultas SQL en una colmena como se menciona a continuación.
select * from student_hbase;
De esta manera, podemos integrar Hive con HBase.
Conclusión - Colmena vs HBase
Como se discutió, ambas son tecnologías diferentes que proporcionan diferentes funcionalidades donde Hive funciona mediante el uso de lenguaje SQL y también se puede llamar como HQL y HBase usan pares clave-valor para analizar los datos. Hive y HBase funcionan mejor si se combinan porque Hive tiene baja latencia y puede procesar una gran cantidad de datos, pero no puede mantener datos actualizados y HBase no admite el análisis de datos, pero admite actualizaciones a nivel de fila en una gran cantidad de datos.
Artículo recomendado
Esta ha sido una guía para Hive vs HBase, su significado, comparación directa, diferencias clave, tabla de comparación y conclusión. También puede consultar los siguientes artículos para obtener más información:
- Apache Pig vs Apache Hive - Top 12 diferencias útiles
- Descubra las 7 mejores diferencias entre Hadoop y HBase
- Top 12 Comparación de Apache Hive vs Apache HBase (Infografía)
- Hadoop vs Hive - Descubre las mejores diferencias