

Introducción a los comandos de Pig
Apache Pig, una herramienta / plataforma que se utiliza para analizar grandes conjuntos de datos y realizar largas series de operaciones de datos. El cerdo se usa con Hadoop. Todos los scripts de cerdo se convierten internamente en tareas de reducción de mapas y luego se ejecutan. Puede manejar datos estructurados, semiestructurados y no estructurados. Tiendas de cerdos, su resultado en HDFS. En este artículo, aprendemos los más tipos de comandos de cerdo.
Estas son algunas características de Pig:
- Optimización automática: Pig puede optimizar los trabajos de ejecución, el usuario tiene la libertad de centrarse en la semántica.
- Facilidad para programar: Pig proporciona un lenguaje / dialecto de alto nivel conocido como Pig Latin, que es fácil de escribir. Pig Latin proporciona muchos operadores, que el programador puede usar para procesar los datos. El programador también tiene la flexibilidad de escribir sus propias funciones.
- Extensible: Pig facilita la creación de funciones personalizadas que se denominan UDF (funciones definidas por el usuario), que hacen que los programadores sean capaces de cumplir cualquier requisito de procesamiento de manera rápida y fácil. El script de Pig se ejecuta en un shell conocido como el gruñido.
¿Por qué los comandos de cerdo?
Los programadores que no son buenos con Java suelen tener dificultades para escribir programas en Hadoop, es decir, escribir tareas de reducción de mapas. Para ellos, Pig Latin, que es bastante parecido al lenguaje SQL, es una bendición. Su enfoque de consultas múltiples reduce la longitud del código.
Entonces, en general, es una forma concisa y efectiva de programación. Los comandos Pig pueden invocar código en muchos idiomas como JRuby, Jython y Java.
La arquitectura de los comandos de cerdo
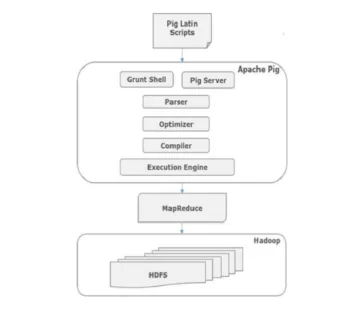
Todos los scripts escritos en Pig-Latin sobre grunt shell van al analizador para verificar la sintaxis y también ocurren otras verificaciones misceláneas. La salida del analizador es un DAG. Este DAG luego se pasa al Optimizador, que luego realiza una optimización lógica como la proyección y empuja hacia abajo. Luego el compilador cumple el plan lógico para los trabajos de MapReduce. Finalmente, estos trabajos de MapReduce se envían a Hadoop en orden ordenado. Estos trabajos se ejecutan y producen los resultados deseados.
El modelo de datos Pig-Latin está completamente anidado y permite tipos de datos complejos, como mapas y tuplas.
Cualquier valor único del lenguaje latino Pig (independientemente del tipo de datos) se conoce como Atom.
Comandos básicos de cerdo
Echemos un vistazo a algunos de los comandos básicos de Pig que se proporcionan a continuación:
1. Fs: Esto mostrará una lista de todos los archivos en el HDFS
gruñido> fs –ls
2. Borrar: Esto borrará el shell interactivo de Grunt.
gruñido> claro
3. Historia:
Este comando muestra los comandos ejecutados hasta ahora.
gruñido> historia
4. Lectura de datos: suponiendo que los datos residen en HDFS, y necesitamos leer los datos en Pig.
gruñido> college_students = LOAD 'hdfs: // localhost: 9000 / pig_data / college_data.txt'
UTILIZANDO PigStorage (', ')
como (id: int, nombre: chararray, apellido: chararray, teléfono: chararray,
ciudad: chararray);
PigStorage () es la función que carga y almacena datos como archivos de texto estructurado.
5. Almacenamiento de datos: el operador de almacenamiento se utiliza para almacenar los datos procesados / cargados.
gruñido> ALMACENAR college_students EN 'hdfs: // localhost: 9000 / pig_Output /' USING PigStorage (', ');
Aquí, "/ pig_Output /" es el directorio donde se debe almacenar la relación.
6. Operador de volcado: este comando se utiliza para mostrar los resultados en la pantalla. Por lo general, ayuda en la depuración.
gruñido> Dump college_students;
7. Describa el operador: ayuda al programador a ver el esquema de la relación.
gruñido> describe college_students;
8. Explique: este comando ayuda a revisar los planes de ejecución lógicos, físicos y de reducción de mapas.
gruñido> explicar college_students;
9. Operador ilustrado: esto proporciona la ejecución paso a paso de las declaraciones en Pig Commands.
gruñido> ilustrar college_students;
Comandos intermedios de cerdo
1. Agrupar: este comando Pig funciona para agrupar datos con la misma clave.
gruñido> group_data = GROUP college_students por nombre;
2. GRUPO: Funciona de manera similar al operador del grupo. La principal diferencia entre el operador de grupo y de grupo es que el operador de grupo generalmente se usa con una relación, mientras que el grupo se usa con más de una relación.
3. Unir: se utiliza para combinar dos o más relaciones.
Ejemplo: para realizar la autounión, digamos que la relación "cliente" se carga desde los comandos HDFS tp pig en dos relaciones clientes1 y clientes2.
gruñido> clientes3 = UNIRSE a clientes1 POR id, clientes2 POR id;
La unión podría ser autounión, unión interna, unión externa.
4. Cruz: este comando de cerdo calcula el producto cruzado de dos o más relaciones.
gruñido> cross_data = clientes CRUZADOS, pedidos;
5. Unión: fusiona dos relaciones. La condición para la fusión es que tanto las columnas como los dominios de la relación deben ser idénticos.
gruñido> estudiante = UNIÓN estudiante1, estudiante2;
Comandos avanzados de cerdo
Echemos un vistazo a algunos de los comandos avanzados de Pig que se proporcionan a continuación:
1. Filtro: esto ayuda a filtrar las tuplas fuera de relación, según ciertas condiciones.
filter_data = FILTRO college_students POR ciudad == 'Chennai';
2. Distinto: Esto ayuda a eliminar tuplas redundantes de la relación.
gruñido> distinct_data = DISTINCT college_students;
Este filtrado creará un nuevo nombre de relación "distinct_data"
3. Foreach: esto ayuda a generar la transformación de datos basada en datos de columna.
gruñido> foreach_data = PARA TODOS los detalles del estudiante GENERAR id, edad, ciudad;
Esto obtendrá los valores de id, edad y ciudad de cada alumno de la relación student_details y, por lo tanto, lo almacenará en otra relación denominada foreach_data.
4. Ordenar por: Este comando muestra el resultado en un orden ordenado basado en uno o más campos.
gruñido> order_by_data = ORDEN college_students POR edad DESC;
Esto ordenará la relación "college_students" en orden descendente por edad.
5. Límite: este comando se limita no. de tuplas de la relación.
gruñido> limit_data = LIMIT student_details 4;
Consejos y trucos
A continuación se presentan los diferentes consejos y trucos de los comandos de Pig: -
1. Habilite la compresión en su entrada y salida:
set input.compression.enabled true;
establecer output.compression.enabled verdadero;
Las líneas de código mencionadas anteriormente deben estar al comienzo de la secuencia de comandos, para que los comandos de Pig puedan leer archivos comprimidos o generar archivos comprimidos como salida.
2. Unir múltiples relaciones:
Para realizar la unión izquierda en digamos tres relaciones (input1, input2, input3), uno debe optar por SQL. Es porque la unión externa no es compatible con Pig en más de dos tablas.
En vez de eso, realiza la izquierda para unirte en dos pasos como:
data1 = JOIN input1 BY key LEFT, input2 BY key;
data2 = JOIN data1 BY input1 :: key LEFT, input3 BY key;
Esto significa dos trabajos de reducción de mapas.
Para realizar la tarea anterior de manera más efectiva, uno puede optar por "Cogroup". Cogroup puede unir múltiples relaciones. El grupo por defecto realiza la unión externa.
Conclusión
Pig es un lenguaje de procedimiento, generalmente utilizado por científicos de datos para realizar procesamiento ad-hoc y creación rápida de prototipos. Es una gran herramienta de procesamiento de ETL y big data. Los scripts de Pig pueden ser invocados por otros idiomas y viceversa. Por lo tanto, los comandos Pig se pueden usar para crear aplicaciones más grandes y complejas.
Artículos recomendados
Esta ha sido una guía para los comandos de Pig. Aquí hemos discutido los comandos básicos y avanzados de Pig y algunos comandos inmediatos de Pig. También puede consultar el siguiente artículo para obtener más información:
- Comandos de Adobe Photoshop
- Comandos de Tableau
- Cheat sheet SQL (comandos, consejos gratuitos y trucos)
- Comandos de VBA: toques finales
- Diferentes operaciones relacionadas con tuplas