

Diferencia entre Hadoop y Hive
Hadoop
Hadoop es un Framework o Software que se inventó para administrar grandes datos o Big Data. Hadoop se utiliza para almacenar y procesar los datos grandes distribuidos en un grupo de servidores básicos.
Hadoop almacena los datos utilizando el sistema de archivos distribuidos de Hadoop y los procesa / consulta utilizando el modelo de programación Map Reduce.
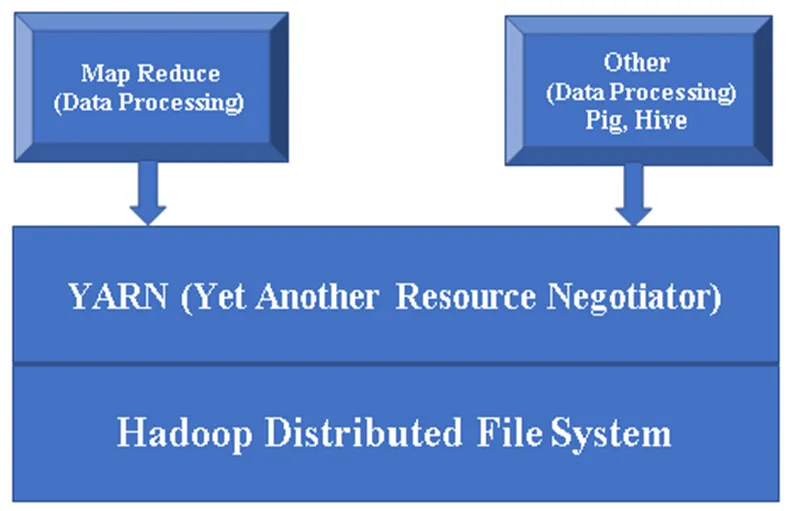
Figura 1, una arquitectura básica de un componente Hadoop.
Componentes principales de Hadoop:
Hadoop Base / Common: Hadoop common le proporcionará una plataforma para instalar todos sus componentes.
HDFS (Sistema de archivos distribuidos de Hadoop): HDFS es una parte importante del marco de trabajo de Hadoop, se encarga de todos los datos en Hadoop Cluster. Funciona en la arquitectura maestro / esclavo y almacena los datos mediante la replicación.
Master / Slave Architecture & Replication:
- Nodo maestro / Nodo de nombre: el nodo Nombre almacena los metadatos de cada bloque / archivo almacenado en HDFS, HDFS solo puede tener un Nodo maestro (en caso de HA, otro Nodo maestro funcionará como Nodo maestro secundario).
- Nodo esclavo / Nodo de datos: los nodos de datos contienen archivos de datos reales en bloques. HDFS puede tener múltiples nodos de datos.
- Replicación: HDFS almacena sus datos dividiéndolos en bloques. El tamaño de bloque predeterminado es de 64 MB. Debido a que los datos de replicación se almacenan en 3 (factor de replicación predeterminado, se puede aumentar según el requisito) diferentes nodos de datos, por lo tanto, existe la menor posibilidad de perder los datos en caso de falla de cualquier nodo.
YARN (Otro negociador de recursos): se utiliza básicamente para administrar los recursos de Hadoop y también juega un papel importante en la programación de la aplicación de los usuarios.
MR (Map Reduce): este es el modelo básico de programación de Hadoop. Se utiliza para procesar / consultar los datos dentro del marco Hadoop.
Colmena:
Hive es una aplicación que se ejecuta sobre el marco de Hadoop y proporciona una interfaz similar a SQL para procesar / consultar los datos. Hive está diseñado y desarrollado por Facebook antes de convertirse en parte del proyecto Apache-Hadoop.
Hive ejecuta su consulta usando HQL (lenguaje de consulta Hive). Hive tiene la misma estructura que RDBMS y se pueden usar casi los mismos comandos en Hive.
Hive puede almacenar los datos en tablas externas, por lo que no es obligatorio usar HDFS, también admite formatos de archivo como ORC, archivos Avro, archivos de secuencia y archivos de texto, etc.
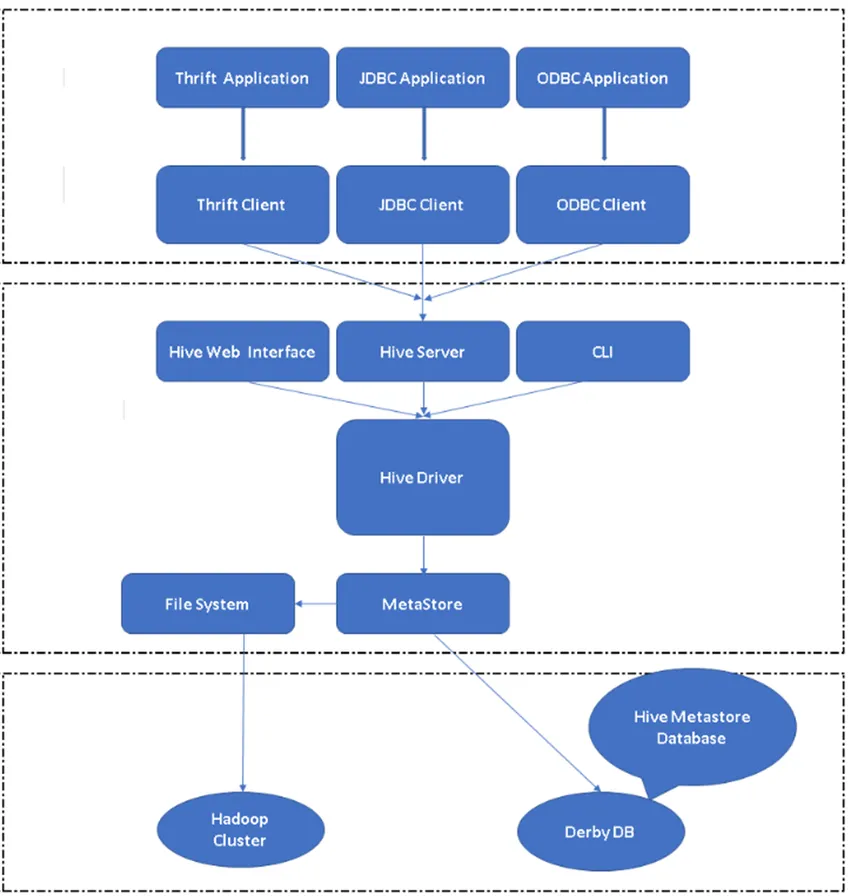
Figura 2, Arquitectura de la colmena y sus componentes principales.
Componente principal de la colmena:
Clientes de Hive: no solo SQL, Hive también admite lenguajes de programación como Java, C, Python usando varios controladores como ODBC, JDBC y Thrift. Se puede escribir cualquier aplicación de cliente de Hive en otros idiomas y se puede ejecutar en Hive con estos clientes.
Servicios de Hive: en los servicios de Hive, se lleva a cabo la ejecución de comandos y consultas. La interfaz web de Hive tiene cinco subcomponentes.
- CLI: interfaz de línea de comandos predeterminada proporcionada por Hive para la ejecución de consultas / comandos de Hive.
- Interfaces web de Hive: es una interfaz gráfica de usuario simple. Es una alternativa a la línea de comandos de Hive y se utiliza para ejecutar las consultas y los comandos en la aplicación Hive.
- Servidor Hive: también se llama Apache Thrift. Es responsable de tomar comandos de diferentes interfaces de línea de comandos y enviar todos los comandos / consultas a Hive, también recupera el resultado final.
- Apache Hive Driver: es responsable de tomar las entradas de las interfaces CLI, UI web, ODBC, JDBC o Thrift por un cliente y pasar la información al metastore donde se almacena toda la información del archivo.
- Metastore: Metastore es un repositorio para almacenar toda la información de metadatos de Hive. Los metadatos de Hive almacenan información como la estructura de tablas, particiones y tipo de columna, etc.
Almacenamiento de Hive: es la ubicación donde se realiza la tarea real. Todas las consultas que se ejecutan desde Hive realizan la acción dentro del almacenamiento de Hive.
Comparación cabeza a cabeza entre Hadoop y Hive (infografía)
A continuación se muestra la diferencia de 8 principales entre Hadoop vs Hive
Diferencias clave entre Hadoop y Hive:
A continuación se encuentran las listas de puntos, describa las diferencias clave entre Hadoop y Hive:
1) Hadoop es un marco para procesar / consultar los datos grandes, mientras que Hive es una herramienta basada en SQL que se construye sobre Hadoop para procesar los datos.
2) Procesar / consultar todos los datos de Hive usando HQL (Hive Query Language) es un lenguaje similar a SQL, mientras que Hadoop solo puede entender Map Reduce.
3) Map Reduce es una parte integral de Hadoop, la consulta de Hive se convierte primero en Map Reduce que procesa Hadoop para consultar los datos.
4) Hive funciona en consultas SQL Like, mientras que Hadoop lo entiende usando solo Map Reduce basado en Java.
5) En Hive, los comandos tradicionales de "Base de datos relacional" utilizados anteriormente también se pueden utilizar para consultar los datos grandes, mientras que en Hadoop, tienen que escribir programas complejos de Map Reduce utilizando Java, que no es similar a la tradición Java.
6) Hive solo puede procesar / consultar los datos estructurados, mientras que Hadoop está diseñado para todo tipo de datos, ya sea estructurados, no estructurados o semiestructurados.
7) Usando Hive, uno puede procesar / consultar los datos sin programación compleja, mientras que en el ecosistema Simple Hadoop, necesita escribir un programa Java complejo para los mismos datos.
8) Los marcos de Hadoop de un lado necesitan una línea de 100s para preparar el programa de MR basado en Java, otro lado de Hadoop con Hive puede consultar los mismos datos usando 8 a 10 líneas de HQL.
9) En Hive, es muy difícil insertar la salida de una consulta como entrada de otra, mientras que la misma consulta se puede hacer fácilmente usando Hadoop con MR.
10) No es obligatorio tener Metastore dentro del clúster de Hadoop, mientras que Hadoop almacena todos sus metadatos dentro de HDFS (Hadoop Distributed File System).
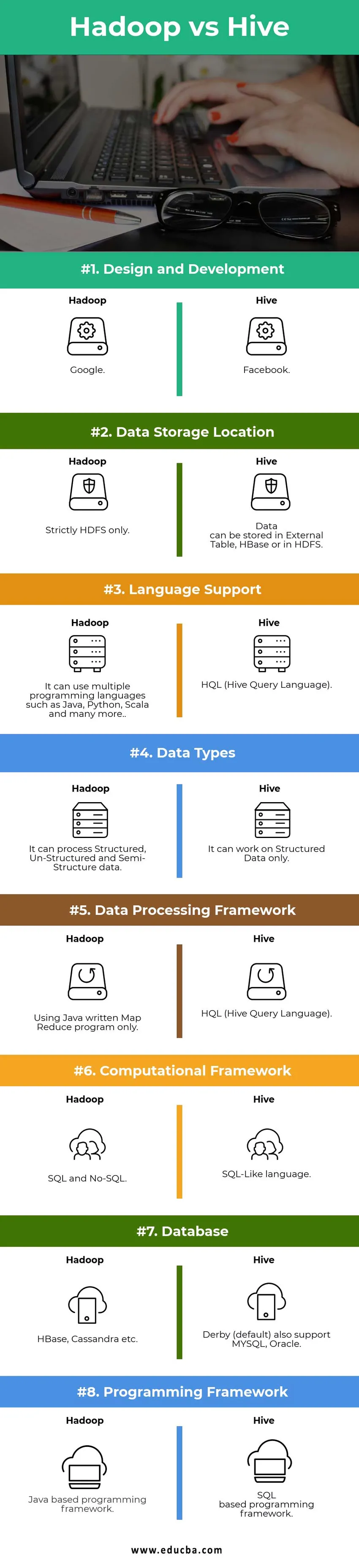
Tabla de comparación de Hadoop vs Hive
| Puntos de comparación | Colmena | Hadoop |
|
Diseño y desarrollo | ||
| Ubicación de almacenamiento de datos |
Los datos se pueden almacenar en Externo Tabla, HBase o en HDFS. | Estrictamente solo HDFS. |
| Ayuda de idioma | HQL (lenguaje de consulta de Hive) |
Puede usar múltiples lenguajes de programación como Java, Python, Scala y muchos más. |
| Tipos de datos | Solo puede funcionar en datos estructurados. |
Puede procesar datos estructurados, no estructurados y semiestructurados. |
| Marco de procesamiento de datos |
HQL (lenguaje de consulta de Hive) | Uso del programa Map Reduce escrito en Java solamente. |
|
Marco computacional | Lenguaje tipo SQL. | SQL y No-SQL. |
| Base de datos |
Derby (predeterminado) también es compatible con MYSQL, Oracle … | HBase, Cassandra, etc. |
| Marco de programación |
Marco de programación basado en SQL. | Marco de programación basado en Java. |
Conclusión - Hadoop vs Hive
Hadoop y Hive se utilizan para procesar los datos grandes. Hadoop es un marco que proporciona una plataforma para que otras aplicaciones consulten / procesen Big Data, mientras que Hive es solo una aplicación basada en SQL que procesa los datos usando HQL (Hive Query Language)
Hadoop se puede usar sin Hive para procesar los datos grandes, mientras que no es fácil usar Hiveop sin Hadoop.
Como conclusión, no podemos comparar Hadoop y Hive de ninguna manera y en ningún aspecto. Tanto Hadoop como Hive son completamente diferentes. Ejecutar ambas tecnologías juntas puede hacer que el proceso de consulta de Big Data sea mucho más fácil y cómodo para los usuarios de Big Data.
Artículos recomendados:
Esta ha sido una guía de Hadoop vs Hive, su significado, comparación cabeza a cabeza, diferencias clave, tabla de comparación y conclusión. También puede consultar los siguientes artículos para obtener más información:
- Hadoop vs Apache Spark: cosas interesantes que debes saber
- HADOOP vs RDBMS | Conozca las 12 diferencias útiles
- Cómo Big Data está cambiando la cara de la atención médica
- Top 12 Comparación de Apache Hive vs Apache HBase (Infografía)
- Guía increíble en Hadoop vs Spark