

Introducción a la arquitectura Hadoop
Hadoop Architecture es un marco de código abierto que ayuda a procesar fácilmente grandes conjuntos de datos. Ayuda a crear aplicaciones que procesan grandes datos con más velocidad. Hace uso de los conceptos de computación distribuida donde los datos se extienden a través de diferentes nodos de un clúster. Las aplicaciones que se crean con Hadoop utilizan computadoras de consumo. Estas computadoras están disponibles fácilmente en el mercado a precios económicos. Este resultado está logrando una mayor potencia computacional a bajo costo. Todos los datos presentes en Hadoop residen en HDFS en lugar de un sistema de archivos local. HDFS es un sistema de archivos distribuido de Hadoop. Este modelo se basa en la Localidad de datos donde la lógica computacional se envía a los nodos presentes en un clúster que contiene los datos. Esta lógica no es más que una lógica que compila el programa.
Arquitectura Hadoop
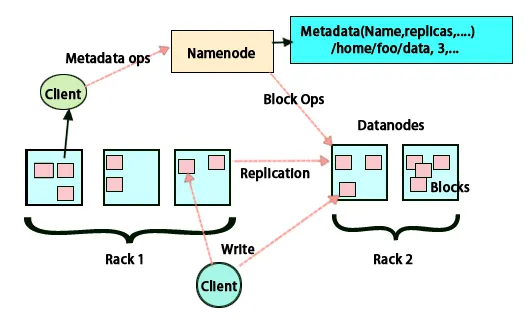
La idea básica de esta arquitectura es que todo el almacenamiento y procesamiento se realiza en dos pasos y de dos maneras. El primer paso es el procesamiento que se realiza mediante la programación de reducción de mapas y el segundo paso es almacenar los datos que se realizan en HDFS. Tiene una arquitectura maestro-esclavo para almacenamiento y procesamiento de datos. El nodo maestro para el almacenamiento de datos en Hadoop es el nodo de nombre. También hay un nodo maestro que hace el trabajo de monitoreo y procesamiento paralelo de datos al hacer uso de Hadoop Map Reduce. Los esclavos son otras máquinas en el clúster de Hadoop que ayudan a almacenar datos y también realizan cálculos complejos. A cada nodo esclavo se le ha asignado un rastreador de tareas y un nodo de datos tiene un rastreador de trabajos que ayuda a ejecutar los procesos y sincronizarlos de manera efectiva. Este tipo de sistema se puede configurar en la nube o en las instalaciones. El nodo Nombre es un punto único de falla cuando no se ejecuta en modo de alta disponibilidad. La arquitectura Hadoop también tiene provisiones para mantener un nodo Nombre en espera para proteger el sistema de fallas. Anteriormente, había nodos de nombres secundarios que actuaban como respaldo cuando el nodo de nombres primario estaba inactivo.
FSimage y Editar registro
FSimage y Edit Log aseguran la persistencia de los metadatos del sistema de archivos para mantenerse al día con toda la información y el nodo de nombre almacena los metadatos en dos archivos. Estos archivos son FSimage y el registro de edición. El trabajo de FSimage es mantener una instantánea completa del sistema de archivos en un momento dado. Es necesario mantener un registro de los cambios que se realizan constantemente en un sistema. Estos cambios incrementales como renombrar o agregar detalles al archivo se almacenan en el registro de edición. El marco proporciona una mejor opción en lugar de crear una nueva imagen FS cada vez, una mejor opción es poder almacenar los datos mientras se crea un nuevo archivo para FSimage. FSimage crea una nueva instantánea cada vez que se realizan cambios Si el nodo Nombre falla, puede restaurar su estado anterior. El nodo de nombre secundario también puede actualizar su copia siempre que haya cambios en FSimage y edite registros. Por lo tanto, asegura que aunque el nodo de nombre esté inactivo, en presencia de un nodo de nombre secundario no habrá ninguna pérdida de datos. El nodo de nombre no requiere que estas imágenes tengan que volver a cargarse en el nodo de nombre secundario.
Replicación de datos
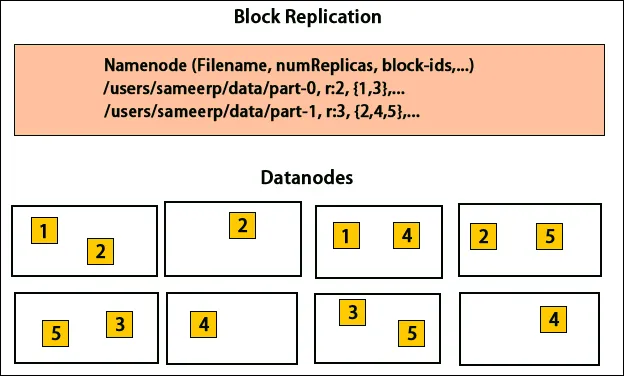
HDFS está diseñado para procesar datos rápidamente y proporcionar datos confiables. Almacena datos en máquinas y en grandes grupos. Todos los archivos se almacenan en una serie de bloques. Estos bloques se replican para tolerancia a fallas. El tamaño del bloque y el factor de replicación pueden ser decididos por los usuarios y configurados según los requisitos del usuario. Por defecto, el factor de replicación es 3. El factor de replicación puede especificarse en el momento de la creación del archivo y puede cambiarse más adelante. Todas las decisiones con respecto a estas réplicas son tomadas por el nodo de nombre. El nodo de nombre sigue enviando latidos e informes de bloque a intervalos regulares para todos los nodos de datos en el clúster. La recepción de latidos implica que el nodo de datos funciona correctamente. El informe de bloque especifica la lista de todos los bloques presentes en el nodo de datos.
Colocación de réplicas
La colocación de réplicas es una tarea muy importante en Hadoop para la confiabilidad y el rendimiento. Todos los diferentes bloques de datos se colocan en diferentes bastidores. La implementación de la ubicación de la réplica se puede realizar según la confiabilidad, la disponibilidad y la utilización del ancho de banda de la red. El grupo de computadoras se puede distribuir en diferentes bastidores. No se pueden colocar más de dos nodos en el mismo bastidor. La tercera réplica se debe colocar en un bastidor diferente para garantizar una mayor fiabilidad de los datos. Los dos nodos en el bastidor se comunican a través de diferentes conmutadores. El nodo de nombre tiene la identificación del bastidor para cada nodo de datos. Pero colocar todos los nodos en diferentes racks evita la pérdida de datos y permite el uso del ancho de banda de múltiples racks. También corta el tráfico entre bastidores y mejora el rendimiento. Además, la posibilidad de falla del bastidor es muy menor en comparación con la de la falla del nodo. Reduce el ancho de banda agregado de la red cuando los datos se leen desde dos bastidores únicos en lugar de tres.
Mapa reducido
Map Reduce se utiliza para procesar datos que se almacenan en HDFS. Escribe datos distribuidos a través de aplicaciones distribuidas que aseguran un procesamiento eficiente de grandes cantidades de datos. Procesan en grandes grupos y requieren productos que sean confiables y tolerantes a fallas. El núcleo de Map-reduce puede ser tres operaciones como mapeo, recopilación de pares y barajar los datos resultantes.
Conclusión - Arquitectura Hadoop
Hadoop es un marco de código abierto que ayuda en un sistema tolerante a fallas. Puede almacenar grandes cantidades de datos y ayuda a almacenar datos confiables. Las dos partes de almacenar datos en HDFS y procesarlos a través del mapa reducen la ayuda para trabajar de manera adecuada y eficiente. Tiene una arquitectura que ayuda a administrar todos los bloques de datos y también a tener la copia más reciente al almacenarla en FSimage y editar registros. El factor de replicación también ayuda a tener copias de datos y recuperarlos cada vez que hay una falla. HDFS también mueve los archivos eliminados al directorio de la papelera para un uso óptimo del espacio.
Artículos recomendados
Esta ha sido una guía de la arquitectura Hadoop. Aquí hemos discutido la Arquitectura, Reducción de mapas, Colocación de réplicas, Replicación de datos. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Conviértete en un desarrollador de Hadoop
- Introducción a Android
- ¿Qué es el cuadro? El | Una visión general
- ¿Qué es MapReduce en Hadoop?