

Cómo instalar Apache
Antes de ingresar a cómo instalar la parte de Apache, primero tendríamos una descripción general de Apache y cómo se usa en la ciencia de datos.
¿Qué es apache?

Apache Web Server es un servidor HTTP que presenta sitios web a los visitantes que acuden a su servidor. Entonces, si desea implementar un sitio web para una empresa o su organización, lo más probable es que use Apache para eso.
Existen otros servidores HTTP, como IIS, pero Apache es el estándar que usa la mayoría de las personas, ya sea en Linux, Windows o Mac. Apache es el valor predeterminado al que recurre la mayoría de las personas porque es bien conocido, es muy confiable y es gratis.
Sin embargo, una cosa a tener en cuenta con Apache es que, como es un servidor HTTP, por lo que si instala esto en Linux, Windows o Mac, todo lo que le permitiría hacer es presentar sitios web estáticos a los visitantes que visiten su servidor. Por lo tanto, si codifica un sitio web HTML sin lenguajes de programación adicionales que no sean JavaScript, puede usarlo solo con un servidor Apache. Puede conectar todas sus etiquetas en el servidor Apache y presentarlas a sus visitantes.
¿Cómo utilizó Apache en Data Science?
Data Science es el campo de estudio más solicitado en el mundo moderno. Data Scientist es considerado el trabajo más sexy del siglo XXI con profesionales de diversas disciplinas que desean aprender y convertirse en Data Scientist. Apache desempeña un papel crucial en cualquier entusiasta de la ciencia de datos, ya que necesitan un conocimiento suficiente del ecosistema Apache Hadoop.
Ecosistema Apache Hadoop
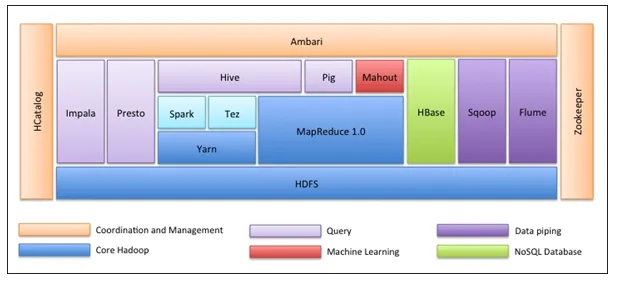
Lo primero es que el ecosistema Hadoop no es una herramienta. No es un lenguaje de programación o un marco único. Es un grupo de herramientas que son utilizadas juntas por varias compañías en diferentes dominios para múltiples tareas. Examinaremos cada herramienta una por una a continuación: -
- Apache HDFS (Hadoop Distributed File System) es la unidad de almacenamiento de Hadoop que puede almacenar datos estructurados, semiestructurados y no estructurados. HDFS tiene metadatos que mantienen el archivo de registro sobre los datos almacenados. Tiene dos componentes: NameNode y DataNode.
- Apache Yarn es el negociador de recursos que realiza todas las actividades de procesamiento, como programar tareas, asignar recursos, etc. Tiene dos servicios: primero, el Administrador de recursos que programa las aplicaciones que se ejecutan sobre Yarn. El segundo es el Administrador de nodos que supervisa la utilización de recursos .
- Apache Map Reduce es el componente de procesamiento de datos de Hadoop que procesa grandes conjuntos de datos utilizando computación distribuida y paralela basada en las funciones Map, Sort and Shuffle y Reduce. La función de mapa filtra los datos, luego ordena y se baraja y, al final, la función de reducción agrega agregados y resume el resultado.
- Apache Pig utilizado principalmente en ETL. Tiene dos partes: Pig Latin y Pig runtime. Pig Latin es el lenguaje utilizado para el procesamiento de datos mediante una consulta, mientras que Pig runtime es el entorno de ejecución. Una línea de Pig Latin es casi igual a 100 líneas de código Map Reduce. El proceso implica primero cargar los datos y luego agruparlos, clasificarlos, filtrarlos y almacenarlos en HDFS.
- Apache Hive utiliza una consulta similar a SQL para analizar datos en un entorno distribuido. Tiene dos componentes: la línea de comandos de Hive y el servidor JDBC / ODBC y el lenguaje utilizado se llama HiveQL.
- Apache Mahout es la biblioteca de Machine Learning escrita en Java y utilizada para crear aplicaciones de machine learning como clustering, clasificación o regresión. Tiene diferentes algoritmos incorporados para diferentes casos de uso.
- Apache HBase es una base de datos NoSQL escrita en Java que se ejecuta sobre Hadoop. Está construido en base a BigTable de Google y es capaz de manejar todo tipo de datos.
- Apache Sqoop es una herramienta de ingestión de datos que se utiliza para la transferencia de datos estructurados en masa entre RDBMS y Hadoop.
- Apache Flume es otra herramienta de ingestión de datos que se utiliza para la transferencia de datos semiestructurada y no estructurada entre Hadoop y otras fuentes de datos.
- ZooKeeper es el coordinador que garantiza la coordinación entre varias herramientas en el ecosistema de Hadoop.
- Apache Ambari es un administrador de clústeres que aprovisiona, administra clústeres de Hadoop y también monitorea su estado y salud.
- Apache Tez es una nueva herramienta en el ecosistema de Hadoop que acelera el procesamiento de consultas de Hadoop.
- Apache Presto es un motor de consulta SQL distribuido de código abierto que permite la capacidad de consulta multiplataforma.
- Apache HCatalog es un sistema de gestión de tablas y metadatos para Hadoop que permite la interoperabilidad entre las herramientas de procesamiento de datos. También ayuda a los usuarios a elegir las mejores herramientas para sus entornos.
- Apache Spark es el marco más utilizado y popular entre los científicos de datos. Es un sistema informático de clúster de alta velocidad que optimiza la utilización de recursos en caso de muchas tareas iterativas. Ofrece flexibilidad tanto para el procesamiento por lotes como para el análisis de datos en tiempo real.
A continuación se detallan los pasos para instalar Apache
Hasta ahora, hemos aprendido sobre Apache y cómo es útil para cualquiera que quiera aprender Data Science o Big Data Analytics. Ahora, profundizaremos e instalaremos apache en Windows según los pasos a continuación.
- Vaya a https://httpd.apache.org/ y haga clic en el enlace Descargar en la sección Apache httpd 2.4.38 Released.

- Le llevará a la siguiente página y luego haga clic en Archivos para Microsoft Windows.
- Haga clic en Apache Lounge.

- Puede descargar 32 o 64 bits del archivo zip según su sistema operativo Windows. Descargaremos la versión de 64 bits aquí. Haga clic en el enlace .zip correspondiente para descargar.

- Ahora, requiere Visual Studio 2017 redistribuible en C ++. Por lo tanto, lo descargaremos del enlace correspondiente de 32 o 64 bits.

- Después de que ambos archivos se hayan descargado, primero iremos a la ubicación descargada e instalaremos C ++ Redistributable Visual Studio 2017. Haga doble clic en el archivo .exe.

- Marque 'Acepto' y haga clic en Instalar.

- La instalación de Apache está en progreso.
- Una vez que esté completo, recibirá un mensaje como este. Haga clic en Cerrar para finalizar la instalación.
- Ahora, vaya a la carpeta donde descarga el archivo zip de Apache. Haga clic derecho sobre él y seleccione extraer aquí.
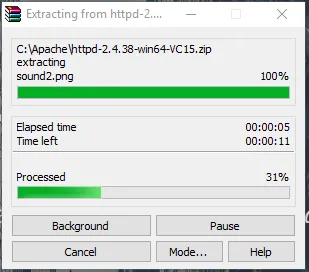
- Ahora, tendremos una carpeta Apache24 creada. Copie esta carpeta en la unidad C y luego agregaremos una ruta a las variables de entorno del sistema.
Vaya a Propiedades del sistema -> pestaña Avanzado -> Haga clic en el botón Variables de entorno a continuación.
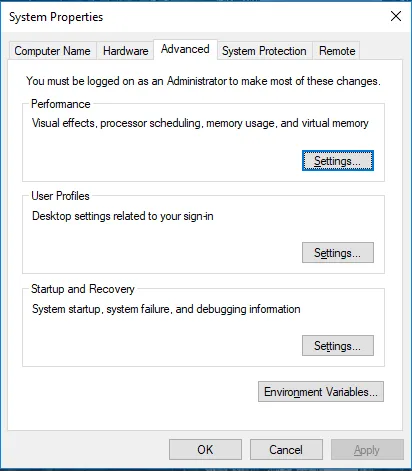
- En Variables, busque Ruta y haga clic en Editar.
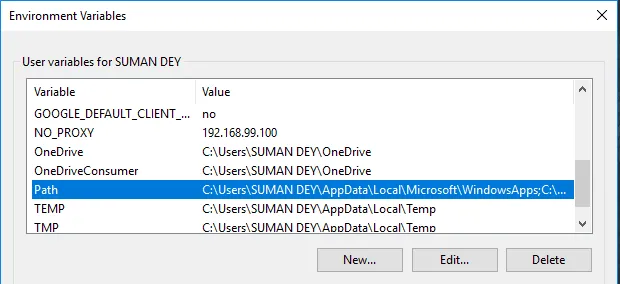
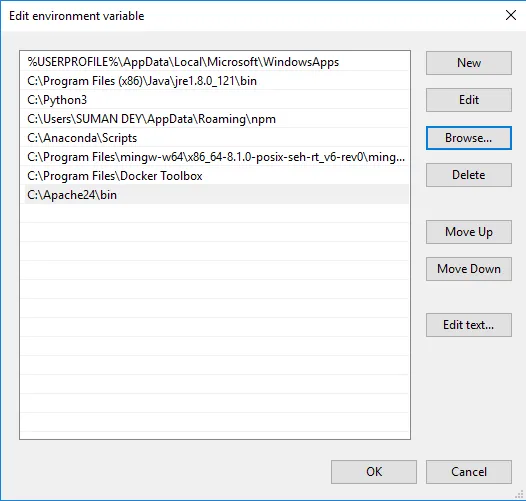
- Haga clic en Examinar -> Ir a la carpeta Apache24 de la unidad C -> Seleccionar carpeta bin -> Haga clic en Aceptar.
- Instalaremos Apache como un servicio de Windows. Ejecute el símbolo del sistema como administrador. Escriba httpd –k install y presione enter.
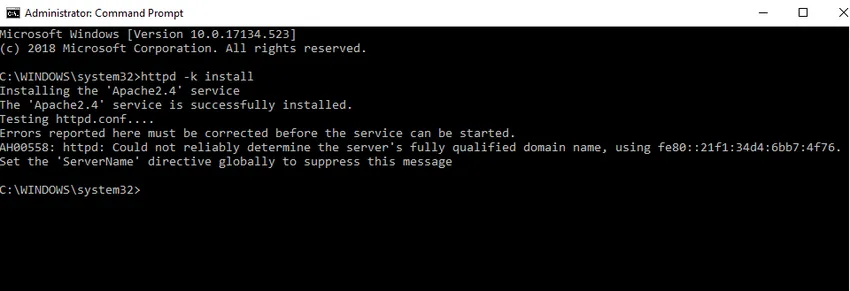
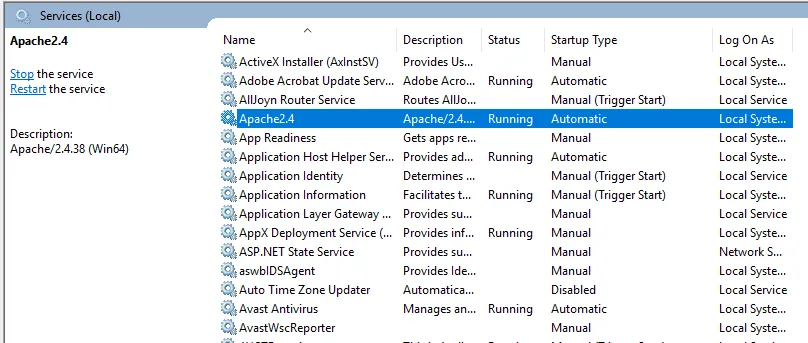
- Comprobaremos el servicio de instalación de Apache. Haga clic en el icono de Windows y escriba servicios. Haga clic en la aplicación Servicios y busque el servicio con el nombre Apache24.

- Para iniciar el servidor Apache, haga clic derecho sobre él y haga clic en iniciar. El estado cambiará a 'En ejecución'.
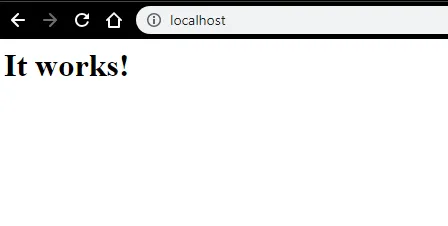
- Podemos probar con un navegador. Abra un navegador y navegue a http: // localhost y presione enter. Un mensaje que dice "¡Funciona!" aparecerá para confirmar la instalación exitosa de Apache.
Artículos recomendados
Esta ha sido una guía sobre cómo instalar Apache. Aquí hemos discutido las instrucciones y los diferentes pasos para instalar Apache. También puede consultar el siguiente artículo para obtener más información:
- Preguntas de la entrevista de Apache
- Apache Spark vs Apache Flink
- Apache Hadoop vs Apache Spark
- Apache Kafka vs Flume
- Kafka vs Kinesis | Principales diferencias