

Introducción a XPath
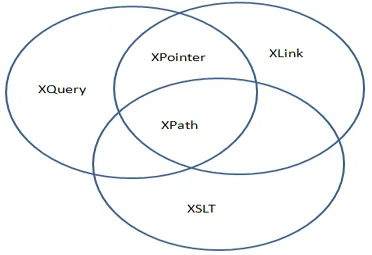
XPath es un componente principal y básico del estándar XSLT. XPath se puede utilizar para recorrer los elementos, atributos, texto, instrucciones de procesamiento, comentarios, espacios de nombres y documentos en un documento de Lenguaje de marcado extensible (XML). Es una recomendación del W3C que contiene una biblioteca con más de 200 funciones integradas. XPath es la sintaxis para definir partes de un documento XML. XSLT es el lenguaje de hoja de estilo para archivos XML. Con XSLT puede transformar documentos XML en otros formatos, como XHTML. XQuery se trata de consultar datos XML. XQuery está diseñado para consultar cualquier cosa que pueda aparecer como XML, incluidas las bases de datos. La vinculación en XML se divide en dos partes: XLink y XPointer. XLink y XPointer definen una forma estándar de crear hipervínculos en documentos XML.
Expresión de XPath
XPath permite diferentes tipos de expresiones para recuperar información relevante del documento XML. XPath aborda una parte específica del documento. Modela un documento XML como un árbol de nodos. Una expresión de XPath es una técnica para navegar y seleccionar nodos del documento.
Las expresiones XPath se pueden usar en C, C ++, Python, Java, JavaScript, PHP, Esquema XML y muchos otros lenguajes. Una expresión XPath se refiere a un patrón para seleccionar un conjunto de nodos. XPointer utiliza estos patrones para abordar el propósito o realizar transformaciones por XSLT. La expresión XPath especifica siete tipos de nodos que pueden ser el resultado de la ejecución.
1. Raíz
Elemento raíz de un documento XML. Usando las siguientes formas se pueden encontrar elementos raíz.
- Usar comodín (/ *): para seleccionar el nodo raíz
- Usar nombre (/ clase): para seleccionar el nodo raíz por nombre
- Usar nombre con un comodín (/ clase / *): para seleccionar todos los elementos bajo el nodo raíz
Código:
2. Elemento
Nodo de elemento de un documento XML. A continuación se muestran las formas de encontrar el elemento.
- / class / *: se usa para seleccionar todos los elementos bajo el nodo raíz.
- / class / library: se usa para seleccionar todos los elementos de la biblioteca desde el nodo raíz.
- // biblioteca: se utiliza para seleccionar todo el elemento de la biblioteca del documento.
Código:
3. Atributos
Un atributo de un nodo de elemento en el documento XML recuperado y verificado utilizando el nombre de atributo @ de un elemento.
Código:
4. Texto
Texto de un nodo de elemento en el documento XML, recuperado y verificado por el nombre de un elemento.
Código:
5. Comentario
Ejemplo de comentario
Código:
Nodo o Lista del nodo desde XML
A continuación se incluye la lista de expresiones útiles para seleccionar un nodo o una lista del nodo de un documento XML.
- '/': El uso de esta selección comienza desde el nodo raíz.
- '//': el uso de esta selección comienza desde el nodo actual que coincide con la selección
- '.': Para seleccionar la expresión actual utilizada.
- '..': para seleccionar el nodo principal del nodo actual.
- '@': Para seleccionar atributos.
Ejemplo de XPath
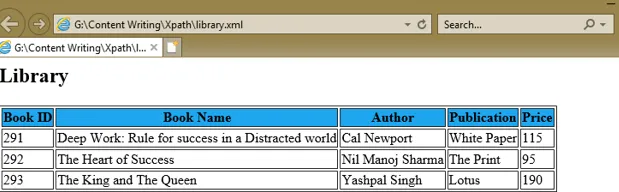
Para comprender una expresión XPath, hemos creado un documento XML, library.xml, y su documento de hoja de estilo library.xsl que usa las expresiones XPath bajo el atributo select de varias etiquetas XSL para obtener los valores de id del libro, nombre del libro, autor, publicación y precio de cada nodo del libro.
1. library.xml
Código:
Deep Work: Rule for success in a Distracted world
Cal Newport
White Paper
115
The Heart of Success
Nil Manoj Sharma
The Print
95
The King and The Queen
Yashpal Singh
Lotus
190
2. library.xsl
Código:
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
| | | | |
|---|---|---|---|---|
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
Salida:
Beneficios de XPath
A continuación se encuentran los beneficios de Xpath:
- Las consultas XPath son simples de escribir y leer y también son compactas.
- La sintaxis XPath es fácil para los casos comunes y simples.
- Las cadenas de consulta se integran fácilmente en scripts, programas y atributos HTML o XML.
- Las consultas XPath se analizan fácilmente.
- Cualquier nodo puede reconocer de forma exclusiva en un documento XML.
- En un documento XML, se puede especificar la aparición de cualquier ruta o cualquier conjunto de condiciones para los nodos en la ruta.
- Las consultas devuelven cualquier número de resultados, incluido cero.
- En un documento XML, las condiciones de consulta se pueden calcular en cualquier nivel y no se supone que atraviesen el nodo superior de un documento XML.
- Las consultas XPath devuelven nodos únicos, no nodos repetidos.
- En muchos contextos, se utiliza XPath para proporcionar enlaces a nodos, para encontrar repositorios y muchas otras aplicaciones.
- Para los programadores, las consultas XPath no son de procedimiento sino más declarativas. Definen cómo se deben atravesar los elementos. Para obtener resultados eficientes, los índices y otras estructuras deben ser utilizados gratuitamente por un optimizador de consultas.
Conclusión
XPath es un lenguaje de consulta utilizado para recorrer elementos, atributos, texto a través de un documento XML. XPath se usa ampliamente para encontrar elementos o atributos particulares con patrones coincidentes. Cuando se define una consulta, los datos XML se pueden representar como un árbol. La representación jerárquica de datos XML se denomina árbol. La parte superior del árbol es un nodo raíz. En un árbol, cada atributo, elementos, texto, comentarios, cadena e instrucción de procesamiento corresponde a un nodo. Las relaciones entre los nodos pueden ser representadas por el árbol.
Artículos recomendados
Esta es una guía de ¿Qué es XPath? Aquí discutimos la expresión, la lista, los ejemplos y los beneficios de Xpath. También puede consultar nuestros otros artículos relacionados para obtener más información.
- ¿Qué es XPath en selenio?
- ¿Qué es el XML?
- Nueva trayectoria profesional
- Carrera de seguridad de la información
- Ejemplos de funciones integradas de Python