

¿Qué es el algoritmo Naive Bayes?
El algoritmo ingenuo de Bayes es una técnica que ayuda a construir clasificadores. Los clasificadores son los modelos que clasifican las instancias del problema y les dan etiquetas de clase que se representan como vectores de predictores o valores de características. Se basa en el teorema de Bayes. Se llama Bayes ingenuo porque supone que el valor de una característica es independiente de la otra característica, es decir, cambiar el valor de una característica no afectaría el valor de la otra característica. También se llama como idiota Bayes debido a la misma razón. Este algoritmo funciona de manera eficiente para grandes conjuntos de datos, por lo tanto, es más adecuado para predicciones en tiempo real.
Ayuda a calcular la probabilidad posterior P (c | x) usando la probabilidad previa de la clase P (c), la probabilidad previa del predictor P (x) y la probabilidad de la clase dada del predictor, también llamada probabilidad P (x | c) )
La fórmula o ecuación para calcular la probabilidad posterior es:
- P (c | x) = (P (x | c) * P (c)) / P (x)
¿Cómo funciona el algoritmo Naive Bayes?
Comprendamos el funcionamiento del algoritmo Naive Bayes utilizando un ejemplo. Asumimos un conjunto de datos de entrenamiento del clima y la variable objetivo 'Ir de compras'. Ahora clasificaremos si una niña irá de compras según las condiciones climáticas.
El conjunto de datos dado es:
| Clima | Ir de compras |
| Soleado | No |
| Lluvioso | si |
| Nublado | si |
| Soleado | si |
| Nublado | si |
| Lluvioso | No |
| Soleado | si |
| Soleado | si |
| Lluvioso | No |
| Lluvioso | si |
| Nublado | si |
| Lluvioso | No |
| Nublado | si |
| Soleado | No |
Se realizarían los siguientes pasos:
Paso 1: Hacer tablas de frecuencia usando conjuntos de datos.
| Clima | si | No |
| Soleado | 3 | 2 |
| Nublado | 4 4 | 0 0 |
| Lluvioso | 2 | 3 |
| Total | 9 9 | 5 5 |
Paso 2: Haz una tabla de probabilidad calculando las probabilidades de cada condición climática e ir de compras.
| Clima | si | No | Probabilidad |
| Soleado | 3 | 2 | 5/14 = 0.36 |
| Nublado | 4 4 | 0 0 | 4/14 = 0.29 |
| Lluvioso | 2 | 3 | 5/14 = 0.36 |
| Total | 9 9 | 5 5 | |
| Probabilidad | 9/14 = 0.64 | 5/14 = 0.36 |
Paso 3: Ahora necesitamos calcular la probabilidad posterior usando la ecuación Naive Bayes para cada clase.
Ejemplo de problema: una niña irá de compras si el clima está nublado. ¿Es correcta esta afirmación?
Solución:
- P (Sí | Cubierto) = (P (Cubierto | Sí) * P (Sí)) / P (Cubierto)
- P (nublado | Sí) = 4/9 = 0.44
- P (Sí) = 9/14 = 0.64
- P (nublado) = 4/14 = 0.39
Ahora ponga todos los valores calculados en la fórmula anterior
- P (Sí | Nublado) = (0.44 * 0.64) / 0.39
- P (Sí | Nublado) = 0.722
La clase con mayor probabilidad sería el resultado de la predicción. Usando el mismo enfoque, se pueden predecir las probabilidades de diferentes clases.
¿Para qué se utiliza el algoritmo Naive Bayes?
1. Predicción en tiempo real: el algoritmo Naive Bayes es rápido y siempre está listo para aprender, por lo tanto, es el más adecuado para las predicciones en tiempo real.
2. Predicción de clases múltiples: la probabilidad de clases múltiples de cualquier variable objetivo puede predecirse utilizando un algoritmo Naive Bayes.
3. Sistema de recomendación: el clasificador Naive Bayes con la ayuda de Collaborative Filtering crea un sistema de recomendación. Este sistema utiliza técnicas de minería de datos y aprendizaje automático para filtrar la información que no se ha visto antes y luego predecir si un usuario apreciaría un recurso dado o no.
4. Clasificación de texto / Análisis de opinión / Filtrado de spam: debido a su mejor rendimiento con problemas de varias clases y su regla de independencia, el algoritmo Naive Bayes funciona mejor o tiene una mayor tasa de éxito en la clasificación de texto, por lo tanto, se utiliza en Análisis de opinión y Filtrado de spam.
Ventajas del algoritmo Naive Bayes
- Fácil de implementar.
- Rápido
- Si se cumple el supuesto de independencia, entonces funciona de manera más eficiente que otros algoritmos.
- Requiere menos datos de entrenamiento.
- Es altamente escalable.
- Puede hacer predicciones probabilísticas.
- Puede manejar datos continuos y discretos.
- Insensible a las características irrelevantes.
- Puede funcionar fácilmente con valores perdidos.
- Fácil de actualizar a la llegada de nuevos datos.
- El más adecuado para problemas de clasificación de texto.
Desventajas del algoritmo Naive Bayes
- La fuerte suposición sobre las características de ser independiente, lo cual no es cierto en las aplicaciones de la vida real.
- Escasez de datos.
- Posibilidades de pérdida de precisión.
- Frecuencia cero, es decir, si la categoría de cualquier variable categórica no se ve en el conjunto de datos de entrenamiento, el modelo asigna una probabilidad cero a esa categoría y luego no se puede hacer una predicción.
Cómo construir un modelo básico usando el algoritmo Naive Bayes
Hay tres tipos de modelos Naive Bayes, es decir, gaussiano, multinomial y bernoulli. Discutamos cada uno de ellos brevemente.
1. Gaussiano: el algoritmo de Bayes ingenuo gaussiano supone que los valores continuos correspondientes a cada característica se distribuyen de acuerdo con la distribución gaussiana, también denominada distribución normal.
Se supone que la probabilidad o probabilidad previa de predicción de la clase dada es gaussiana, por lo tanto, la probabilidad condicional se puede calcular como:
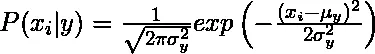
2. Multinomial: las frecuencias de la ocurrencia de ciertos eventos representados por vectores de características se generan mediante distribución multinomial. Este modelo es ampliamente utilizado para la clasificación de documentos.
3. Bernoulli: en este modelo, las entradas se describen por las características que son variables binarias independientes o booleanos. Esto también se usa ampliamente en la clasificación de documentos como Multinomial Naive Bayes.
Puede usar cualquiera de los modelos anteriores según se requiera para manejar y clasificar el conjunto de datos.
Puede construir un modelo gaussiano usando Python entendiendo el ejemplo que se muestra a continuación:
Código:
from sklearn.naive_bayes import GaussianNB
import numpy as np
a = np.array((-2, 7), (1, 2), (1, 5), (2, 3), (1, -1), (-2, 0), (-4, 0), (-2, 2), (3, 7), (1, 1), (-4, 1), (-3, 7)))
b = np.array((3, 3, 3, 3, 4, 3, 4, 3, 3, 3, 4, 4, 4))
md = GaussianNB()
md.fit (a, b)
pd = md.predict (((1, 2), (3, 4)))
print (pd)
Salida:
((3, 4))
Conclusión
En este artículo, aprendimos los conceptos del algoritmo Naive Bayes en detalle. Se utiliza principalmente en la clasificación de texto. Es fácil de implementar y rápido de ejecutar. Su principal inconveniente es que requiere que las características sean independientes, lo que no es cierto en las aplicaciones de la vida real.
Artículos recomendados
Esta ha sido una guía para el algoritmo Naive Bayes. Aquí discutimos el concepto básico, el trabajo, las ventajas y las desventajas del algoritmo Naive Bayes. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Algoritmo de refuerzo
- Algoritmo en Programación
- Introducción al algoritmo