

Introducción al árbol de decisiones en minería de datos
En el mundo de hoy en “Big Data”, el término “Minería de datos” significa que necesitamos analizar grandes conjuntos de datos y realizar “minería” en los datos y sacar a relucir el jugo o la esencia importante de lo que los datos quieren decir. Una situación muy análoga es la de la minería del carbón, donde se requieren diferentes herramientas para extraer el carbón enterrado bajo tierra. De las herramientas en Data mining, el "Árbol de decisiones" es una de ellas. Por lo tanto, la minería de datos en sí misma es un vasto campo en el que en los próximos párrafos profundizaremos en la "herramienta" del Árbol de decisiones en Minería de datos.
Algoritmo del árbol de decisión en minería de datos
Un árbol de decisión es un enfoque de aprendizaje supervisado en el que entrenamos los datos presentes sabiendo cuál es realmente la variable objetivo. Como su nombre indica, este algoritmo tiene un tipo de estructura de árbol. Primero veamos el aspecto teórico del árbol de decisión y luego veamos el mismo en un enfoque gráfico. En el Árbol de decisión, el algoritmo divide el conjunto de datos en subconjuntos en función del atributo más importante o significativo. El atributo más significativo se designa en el nodo raíz y ahí es donde tiene lugar la división de todo el conjunto de datos presente en el nodo raíz. Esta división realizada se conoce como nodos de decisión. En caso de que no sea posible más división, ese nodo se denomina nodo hoja.
Para detener el algoritmo para alcanzar una etapa abrumadora, se emplea un criterio de detención. Uno de los criterios de detención es el número mínimo de observaciones en el nodo antes de que ocurra la división. Al aplicar el árbol de decisión al dividir el conjunto de datos, se debe tener cuidado de que muchos nodos puedan tener datos ruidosos. Para atender problemas de datos atípicos o ruidosos, empleamos técnicas conocidas como poda de datos. La poda de datos no es más que un algoritmo para clasificar los datos del subconjunto que dificulta el aprendizaje de un modelo dado.
El algoritmo del Árbol de decisión fue lanzado como ID3 (dicotomizador iterativo) por el investigador de máquinas J. Ross Quinlan. Más tarde, C4.5 fue lanzado como el sucesor de ID3. Tanto ID3 como C4.5 son un enfoque codicioso. Ahora veamos un diagrama de flujo del algoritmo del Árbol de decisión.
Para nuestra comprensión del pseudocódigo, tomaríamos puntos de datos "n", cada uno con atributos "k". El siguiente diagrama de flujo se realiza teniendo en cuenta la "Ganancia de información" como condición para una división.
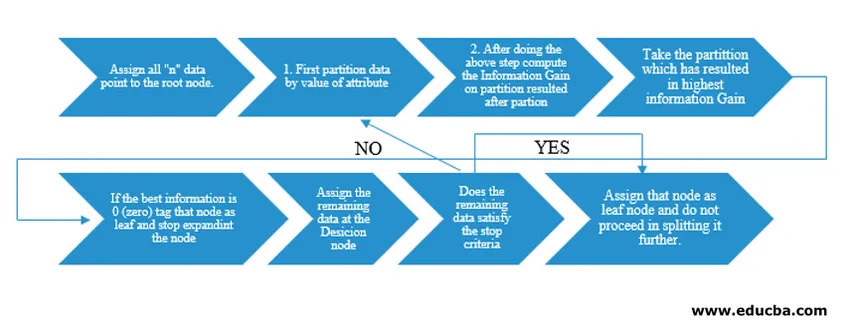
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
En lugar de Ganancia de información (IG), también podemos emplear el Índice de Gini como criterio de división. Para comprender la diferencia entre estos dos criterios en términos simples, podemos pensar en esta ganancia de información como la diferencia de entropía antes de la división y después de la división (división en función de todas las características disponibles).
La entropía es como la aleatoriedad y llegaríamos a un punto después de la división para tener el menor estado de aleatoriedad. Por lo tanto, la ganancia de información debe ser mayor en la función que queremos dividir. De lo contrario, si queremos elegir dividir sobre la base del índice de Gini, encontraríamos el índice de Gini para diferentes atributos y, utilizando el mismo, descubriremos el índice de Gini ponderado para una división diferente y usaremos el que tenga un índice de Gini más alto para dividir el conjunto de datos.
Términos importantes del árbol de decisión en minería de datos
Estos son algunos de los términos importantes de un árbol de decisión en minería de datos que se detallan a continuación:
- Nodo raíz: este es el primer nodo donde tiene lugar la división.
- Nodo de hoja: este es el nodo después del cual no hay más ramificaciones.
- Nodo de decisión: el nodo formado después de dividir los datos de un nodo anterior se conoce como nodo de decisión.
- Rama: subsección de un árbol que contiene información sobre las consecuencias de la división en el nodo de decisión.
- Poda: cuando hay una eliminación de subnodos de un nodo de decisión para atender a un dato atípico o ruidoso, se llama poda. También se cree que es lo opuesto a la división.
Aplicación del árbol de decisión en minería de datos
El Árbol de decisión tiene un tipo de diagrama de flujo de arquitectura incorporado con el tipo de algoritmo. Esencialmente tiene un tipo de patrón "If X then Y else Z" mientras se realiza la división. Este tipo de patrón se utiliza para comprender la intuición humana en el campo programático. Por lo tanto, uno puede usar esto ampliamente en varios problemas de categorización.
- Este algoritmo puede ser ampliamente utilizado en el campo donde la función objetivo está relacionada con el análisis realizado.
- Cuando hay numerosos cursos de acción disponibles.
- Análisis atípico.
- Comprender el conjunto significativo de características para todo el conjunto de datos y "extraer" las pocas características de una lista de cientos de características en Big Data.
- Seleccionando el mejor vuelo para viajar a un destino.
- Proceso de toma de decisiones basado en diferentes situaciones circunstanciales.
- Análisis de rotación.
- Análisis de los sentimientos.
Ventajas del árbol de decisiones
Estas son algunas ventajas del árbol de decisión que se explica a continuación:
- Facilidad de comprensión: la forma en que se representa el árbol de decisión en sus formas gráficas hace que sea fácil de entender para una persona con antecedentes no analíticos. Especialmente para las personas en el liderazgo que desean ver qué características son importantes con solo echar un vistazo al árbol de decisiones pueden sacar a la luz su hipótesis.
- Exploración de datos: como se discutió, la obtención de variables significativas es una funcionalidad central del árbol de decisión y, al usar la misma, uno puede descubrir durante la exploración de datos decidir qué variable necesitaría atención especial durante el curso de la fase de minería de datos y modelado.
- Hay muy poca intervención humana durante la etapa de preparación de datos y, como resultado del tiempo que se consume durante los datos, se reduce la limpieza.
- El Árbol de decisiones es capaz de manejar variables categóricas y numéricas y también atiende problemas de clasificación de varias clases.
- Como parte de la suposición, los árboles de decisión no tienen suposición de una distribución espacial y una estructura de clasificación.
Conclusión
Finalmente, para concluir, los árboles de decisión aportan una clase completamente diferente de no linealidad y se ocupan de resolver problemas de no linealidad. Este algoritmo es la mejor opción para imitar un nivel de decisión pensando en los humanos y representarlo en una forma matemática-gráfica. Toma un enfoque de arriba hacia abajo para determinar los resultados de nuevos datos no vistos y sigue el principio de dividir y conquistar.
Artículos recomendados
Esta es una guía para el Árbol de decisiones en minería de datos. Aquí discutimos el algoritmo, la importancia y la aplicación del árbol de decisión en la minería de datos junto con sus ventajas. También puede consultar los siguientes artículos para obtener más información:
- Aprendizaje automático de ciencia de datos
- Tipos de técnicas de análisis de datos
- Árbol de decisión en R
- ¿Qué es la minería de datos?
- Guía de varias metodologías de análisis de datos