

Diferencias entre Sqoop y Flume
Sqoop es un producto del software Apache. Sqoop extrae información útil de Hadoop y luego la pasa a los almacenes de datos externos. Con la ayuda de Sqoop, podemos importar datos desde un RDBMS o mainframe a HDFS. Flume también es del software Apache. Recopila y mueve los datos recursivos que se generan. Apache Flume no solo se limita a la agregación de datos de registro, sino que las fuentes de datos se pueden personalizar y, por lo tanto, Flume se puede utilizar para transportar cantidades masivas de datos. La mejor manera de recopilar, agregar y mover grandes cantidades de datos entre el Sistema de archivos distribuidos de Hadoop y RDBMS es mediante el uso de herramientas como Sqoop o Flume.
Analicemos estas dos herramientas de uso común para el propósito mencionado anteriormente.
¿Qué es Sqoop?
Para usar Sqoop, un usuario tiene que especificar la herramienta que desea usar y los argumentos que controlan la herramienta en particular. También puede exportar los datos nuevamente a un RDBMS usando Sqoop. La funcionalidad de exportación de Sqoop se utiliza para extraer información útil de Hadoop y exportarla a los almacenes de datos estructurados externos. Funciona con diferentes bases de datos como Teradata, MySQL, Oracle, HSQLDB.
- Arquitectura Sqoop: -
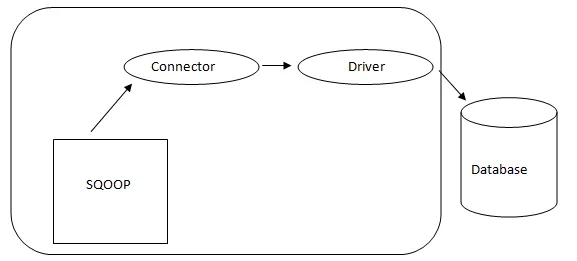
Arquitectura de Sqoop
El conector en un Sqoop es un complemento para una fuente de base de datos particular, por lo que es fundamental que sea una parte del establecimiento de Sqoop. A pesar del hecho de que los controladores son piezas específicas de la base de datos y distribuidas por varios proveedores de bases de datos, Sqoop viene incluido con diferentes tipos de conectores utilizados para el sistema de almacenamiento de información y bases de datos prevalente. Por lo tanto, Sqoop se envía con una variedad mixta de conectores listos para usar también. Sqoop ofrece un componente conectable para una red ideal y un sistema externo. La API de Sqoop brinda una estructura útil para ensamblar nuevos conectores y, por lo tanto, cualquier conector de base de datos se puede colocar en la instalación de Sqoop para brindar conectividad a diferentes sistemas de datos.
¿Qué es el canal?
Apache Flume no solo se limita a la agregación de datos de registro, sino que las fuentes de datos son personalizables y, por lo tanto, Flume se puede usar para transportar cantidades masivas de datos, incluidos, entre otros, mensajes de correo electrónico, datos generados en redes sociales, datos de tráfico de red y prácticamente cualquier fuente de datos posible.
Arquitectura de canal: - La arquitectura de canal se basa en conceptos básicos:
- Evento Flume: se representa como la unidad de flujo de datos, que tiene una carga útil de bytes y un conjunto de cadenas con encabezados de cadena opcionales. Flume considera un evento solo un blob genérico de bytes.
- Flume Agent: es un proceso JVM que aloja los componentes como canales, sumidero y fuentes. Tiene el potencial de recibir, almacenar y reenviar los eventos desde una fuente externa al siguiente nivel.
- Flujo Flujo: es el momento en que se genera el evento.
- Flume Client: se refiere a la interfaz donde el cliente opera en el punto de origen del evento y lo entrega al agente Flume.
- Fuente: una fuente es aquella que consume eventos que tienen un formato específico y los entrega a través de un mecanismo específico.
- Canal: es una tienda pasiva donde se llevan a cabo eventos hasta que el fregadero lo retira para su posterior transporte.
- Sumidero: elimina el evento de un canal y lo coloca en un repositorio externo como HDFS. Actualmente admite la creación de archivos de texto y secuencia y admite la compresión en ambos tipos de archivos.
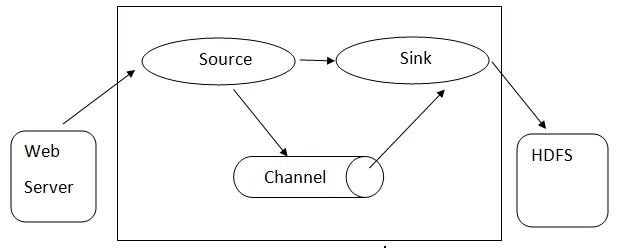
Arquitectura de canal
Comparación cabeza a cabeza entre Sqoop vs Flume (Infografía)
A continuación se muestra la comparación entre los 7 mejores entre Sqoop y Flume

Diferencias clave entre Sqoop vs Flume
Ahora sabemos que hay muchas diferencias entre Sqoop y Flume, a continuación se detallan las diferencias más importantes entre ellas:
1. Sqoop está diseñado para intercambiar información masiva entre Hadoop y la base de datos relacional.
Mientras que Flume se utiliza para recopilar datos de diferentes fuentes que generan datos sobre un caso de uso particular y luego transfieren esta gran cantidad de datos de recursos distribuidos a un único repositorio centralizado.
2. Sqoop también incluye un conjunto de comandos que le permite inspeccionar la base de datos con la que está trabajando. Por lo tanto, podemos considerar Sqoop como una colección de herramientas relacionadas.
Al recopilar la fecha, Flume escala los datos horizontalmente y se pueden poner en acción múltiples agentes Flume para recopilar la fecha y agregarlos. Posteriormente, los registros de datos se mueven a un almacén de datos centralizado, es decir, Hadoop Distributed File System (HDFS).
3. El factor clave para usar Flume es que los datos deben generarse de manera continua y continua. Del mismo modo, Sqoop es el más adecuado en situaciones en las que sus datos viven en sistemas de bases de datos como MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (Tabla de comparación)
| Bases para la comparación | SQOOP | CANAL ARTIFICIAL |
|
Naturaleza básica | Sqoop funciona bien con cualquier RDBMS que tenga JDBC (Java Database Connectivity) como Oracle, MySQL, Teradata, etc. | Flume funciona bien para la fuente de datos de Streaming que se genera continuamente, como registros, JMS, directorio, informes de fallas, etc. |
| Flujo de datos | Sqoop se usa específicamente para la transferencia de datos en paralelo. Por esta razón, la salida podría estar en múltiples archivos | Flume se utiliza para recopilar y agregar datos debido a su naturaleza distribuida. |
| Eventos impulsados | Sqoop no es impulsado por eventos. | El canal está completamente impulsado por eventos. |
| Arquitectura | Sqoop sigue una arquitectura basada en conectores, lo que significa que los conectores saben cómo conectarse a una fuente de datos diferente. | Flume sigue una arquitectura basada en agentes, donde el código escrito en él se conoce como un agente responsable de recuperar datos. |
| Dónde utilizar | Principalmente utilizado para copiar datos más rápido y luego usarlo para generar resultados analíticos. | Generalmente se usa para extraer datos cuando las empresas quieren analizar patrones, causas raíz o análisis de sentimientos utilizando registros y redes sociales. |
| Actuación | Reduce el almacenamiento excesivo y las cargas de procesamiento al transferirlas a otros sistemas y tiene un rendimiento rápido. | Flume es tolerante a fallas, robusto y tiene un mecanismo de confiabilidad sostenible para recuperación de fallas y recuperación. |
| Historial de lanzamientos | La primera versión de Apache Sqoop se lanzó en marzo de 2012. La versión estable actual es 1.4.7 | La primera versión estable 1.2.0 de Apache Flume se lanzó en junio de 2012. La versión estable actual es Apache Flume Versión 1.8.0. |
Conclusión - Sqoop vs Flume
Como aprendió anteriormente, Sqoop y Flume son principalmente dos herramientas de ingestión de datos que se utilizan en el mundo de Big Data. Si necesita ingerir datos de registro textuales en Hadoop / HDFS, Flume es la opción correcta para hacerlo. Si sus datos no se generan regularmente, Flume seguirá funcionando, pero será una exageración para esa situación. Del mismo modo, Sqoop no es la mejor opción para el manejo de datos basado en eventos.
Artículos recomendados
Esta ha sido una guía de las diferencias entre Sqoop y Flume, su significado, comparación directa, diferencias clave, tabla de comparación y conclusión. Este artículo consta de todas las diferencias útiles entre Sqoop y Flume. También puede consultar los siguientes artículos para obtener más información.
- Hadoop vs Teradata: diferencias útiles para aprender
- 5 diferencia más importante entre Apache Kafka vs Flume
- Big Data vs Apache Hadoop: comparación de los 4 principales que debe aprender
- 5 diferencia más importante entre Apache Kafka vs Flume
- Minería de texto importante versus procesamiento del lenguaje natural: las 5 mejores comparaciones