
Introducción del proceso ETL
ETL es uno de los procesos importantes que requiere Business Intelligence. Business Intelligence se basa en los datos almacenados en almacenes de datos a partir de los cuales se generan muchos análisis e informes, lo que ayuda a construir estrategias más efectivas y conduce a ideas tácticas y operativas y a la toma de decisiones.
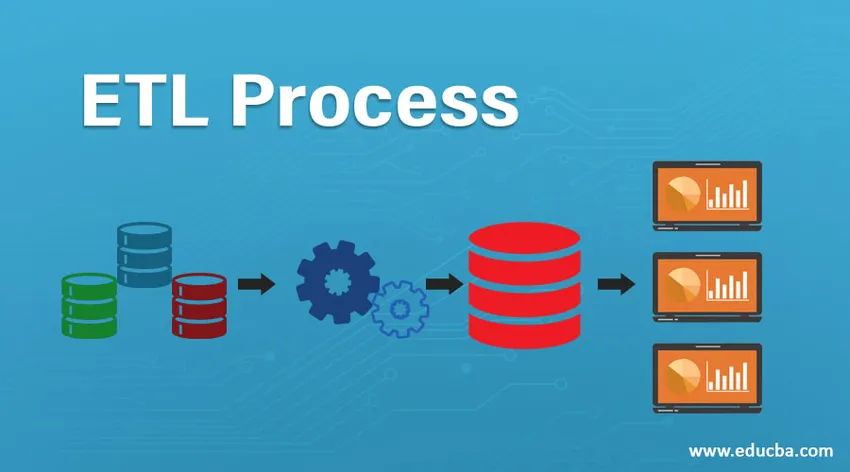
ETL se refiere al proceso de extracción, transformación y carga. Es un tipo de paso de integración de datos donde los datos provenientes de diferentes fuentes se extraen y se envían a los almacenes de datos. Los datos se extraen de varios recursos primero se transforman para convertirlos a un formato específico de acuerdo con los requisitos del negocio. Varias herramientas que ayudan a realizar estas tareas son:
- IBM DataStage
- Abinitio
- Informatica
- Cuadro
- Talend
Proceso ETL
¿Como funciona?
El proceso ETL es un proceso de 3 pasos que comienza con la extracción de datos de varias fuentes de datos y luego los datos sin procesar experimentan varias transformaciones para que sea adecuado para almacenar en el almacén de datos y cargarlo en los almacenes de datos en el formato requerido y prepararlo para análisis.
Paso 1: Extraer
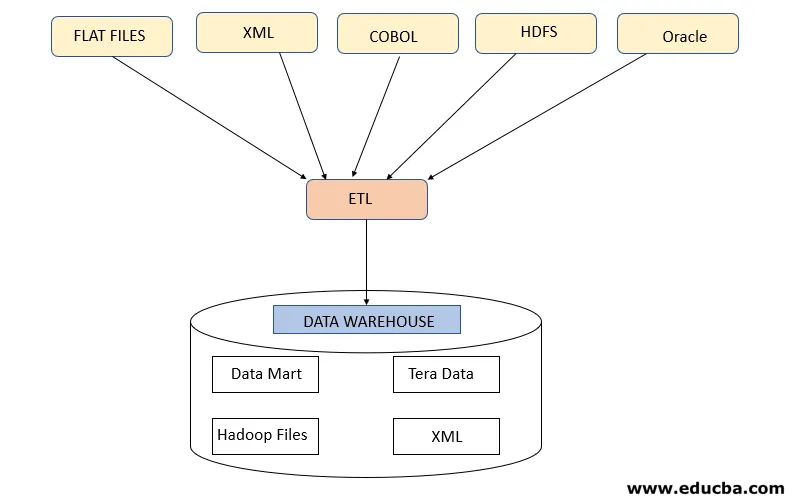
Este paso se refiere a la obtención de los datos requeridos de varias fuentes que están presentes en diferentes formatos, como XML, archivos Hadoop, archivos planos, JSON, etc. Los datos extraídos se almacenan en el área de preparación donde se realizan más transformaciones. Por lo tanto, los datos se verifican a fondo antes de trasladarlos a los almacenes de datos; de lo contrario, será un desafío revertir los cambios en los almacenes de datos.
Se requiere un mapa de datos adecuado entre el origen y el destino antes de que se produzca la extracción de datos, ya que el proceso ETL necesita interactuar con varios sistemas como Oracle, Hardware, Mainframe, sistemas en tiempo real como ATM, Hadoop, etc., mientras se obtienen datos de estos sistemas .
Nota: Pero se debe tener cuidado de que estos sistemas no se vean afectados durante la extracción.
Estrategias de extracción de datos
- Extracción completa: esto se sigue cuando los datos completos de las fuentes se cargan en los almacenes de datos que muestran que el almacén de datos se está rellenando la primera vez o que no se ha hecho una estrategia para la extracción de datos.
- Extracción parcial (con notificación de actualización): esta estrategia también se conoce como delta, donde solo se extraen los datos que se cambian y se actualizan los almacenes de datos
- Extracción parcial (sin notificación de actualización): esta estrategia se refiere a extraer datos específicos requeridos de las fuentes de acuerdo con la carga en los almacenes de datos en lugar de extraer datos completos.
Paso 2: Transformar
Este paso es el más importante de ETL. En este paso, se realizan muchas transformaciones para preparar los datos para la carga en los almacenes de datos mediante la aplicación de las siguientes transformaciones:
A. Transformaciones básicas: estas transformaciones se aplican en cada escenario, ya que son una necesidad básica al cargar los datos que se han extraído de varias fuentes, en los almacenes de datos
- Limpieza o enriquecimiento de datos: se refiere a la limpieza de los datos no deseados del área de preparación para que no se carguen datos incorrectos de los almacenes de datos.
- Filtrado: aquí filtramos los datos requeridos de una gran cantidad de datos presentes de acuerdo con los requisitos comerciales. Por ejemplo, para generar informes de ventas solo se necesitan registros de ventas para ese año específico.
- Consolidación: los datos extraídos se consolidan en el formato requerido antes de cargarlos en los almacenes de datos.
- Normalizaciones: los campos de datos se transforman para que tengan el mismo formato requerido, por ejemplo, el campo de datos debe especificarse como MM / DD / AAAA.
B. Transformaciones avanzadas: este tipo de transformaciones son específicas de los requisitos del negocio.
- Unirse: en esta operación, los datos de 2 o más fuentes se combinan para generar datos con solo las columnas deseadas con filas relacionadas entre sí
- Comprobación de validación del umbral de datos: los valores presentes en varios campos se verifican si son correctos o no, como un número de cuenta bancaria no nulo en el caso de datos bancarios.
- Utilice las búsquedas para fusionar datos: se utilizan varios archivos planos u otros archivos para extraer la información específica mediante la operación de búsqueda en eso.
- Uso de cualquier validación de datos compleja: muchas validaciones complejas se aplican para extraer datos válidos solo de los sistemas de origen.
- Valores calculados y derivados: se aplican varios cálculos para transformar los datos en cierta información requerida
- Duplicación: los datos duplicados procedentes de los sistemas de origen se analizan y eliminan antes de cargarlos en los almacenes de datos.
- Reestructuración de claves: en el caso de capturar datos que cambian lentamente, se deben generar varias claves sustitutas para estructurar los datos en el formato requerido.
Nota : el procesamiento paralelo masivo de MPP se utiliza a veces para realizar algunas operaciones básicas, como el filtrado o la limpieza de datos en el área de preparación para procesar una gran cantidad de datos más rápido.
Paso 3: carga
Este paso se refiere a cargar los datos transformados en el almacén de datos desde donde se pueden utilizar para generar muchas decisiones analíticas, así como informes.
1. Carga inicial: este tipo de carga se produce al cargar datos en almacenes de datos por primera vez.
2. Carga incremental: este es el tipo de carga que se realiza para actualizar el almacén de datos periódicamente con cambios que ocurren en los datos del sistema de origen.
3. Actualización completa: este tipo de carga se refiere a la situación en la que los datos completos de la tabla se eliminan y se cargan con datos nuevos.
El almacén de datos luego permite características OLAP u OLTP.
Desventajas del proceso ETL
- Aumento de datos: la herramienta ETL extrae un límite de datos de varias fuentes y se envía a los almacenes de datos. Por lo tanto, con el aumento de datos, trabajar con la herramienta ETL y los almacenes de datos se vuelven engorrosos.
- Personalización: se refiere a las soluciones o respuestas rápidas y efectivas a los datos generados por los sistemas fuente. Pero el uso de la herramienta ETL aquí ralentiza este proceso.
- Caro: el uso de un almacén de datos para almacenar una cantidad creciente de datos que se generan periódicamente es un costo elevado que una organización debe pagar.
Conclusión - Proceso ETL
La herramienta ETL se compone de procesos de extracción, transformación y carga donde ayuda a generar información a partir de los datos recopilados de varios sistemas fuente. Los datos del sistema fuente pueden venir en cualquier formato y pueden cargarse en cualquier formato deseado en los almacenes de datos, por lo tanto, la herramienta ETL debe admitir la conectividad a todos los tipos de estos formatos.
Artículos recomendados
Esta es una guía para un proceso ETL. Aquí discutimos la introducción, ¿Cómo funciona ?, Herramientas ETL y sus desventajas. También puede consultar nuestros otros artículos sugeridos para obtener más información:
- Herramientas ETL de Informatica
- Herramientas de prueba de ETL
- ¿Qué es el ETL?
- ¿Qué es la prueba ETL?